A year ago, the startup DoNotPay claimed to have built a “robot lawyer” capable of arguing cases before the Supreme Court. There is no evidence that such a technology exists, and attempts to use AI write arguments have ended badly. But DoNotPay’s marketing gimmick was successful in getting wide attention, which goes to show that in the era of large language models, the idea of AI replacing lawyers seems quite plausible to many people.
As we’ve written before, we think such expectations are extremely premature, and we shouldn’t read much into ChatGPT’s performance in simulated scenarios such as the bar exam. We teamed up with our colleague Peter Henderson to write a paper on the promises and pitfalls of AI in law. Peter is a JD/PhD who has thought deeply about these questions and has also successfully built AI for assisting with certain legal tasks. Sayash presented this paper at the conference on Cross-Disciplinary Research in Computational Law (CRCL) and we have submitted it for publication in the CRCL journal.
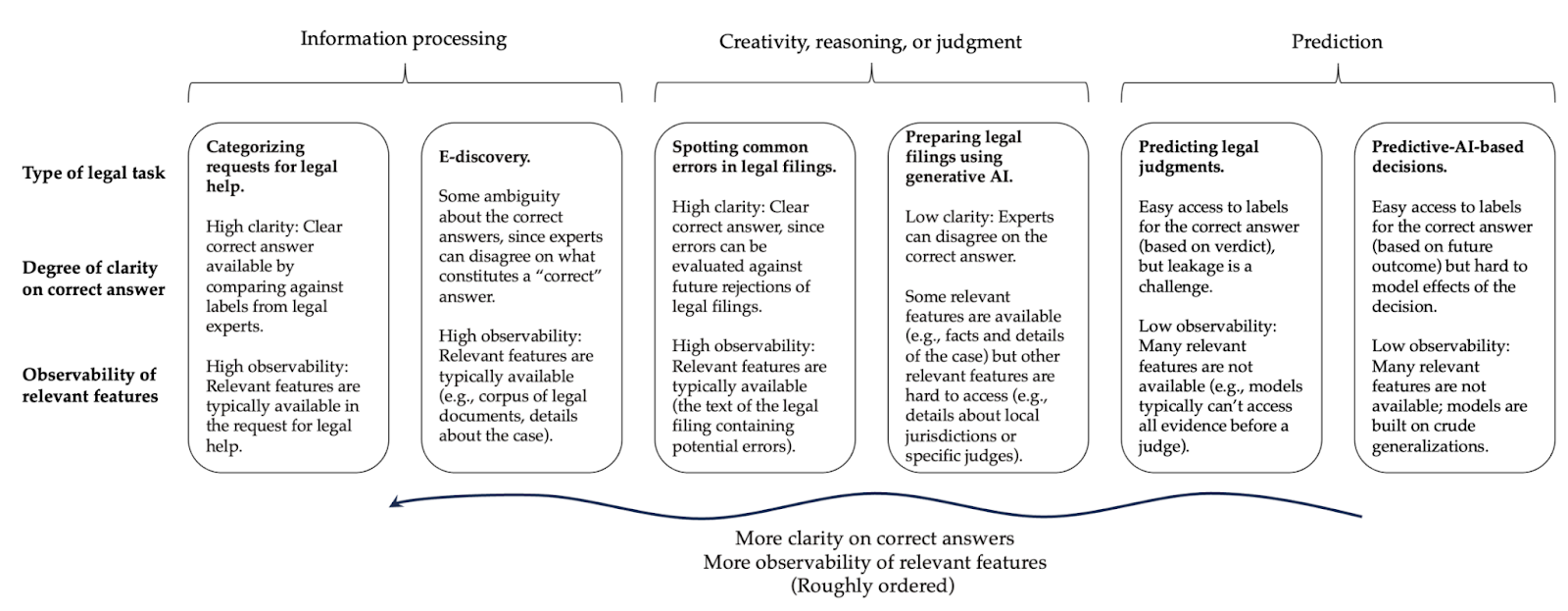
To get clarity on how AI might impact law, we break down the applications into three rough areas. Our key thesis is that the areas that would be most transformative if AI were successful are also harder for AI as well as more prone to overoptimism due to evaluation pitfalls.
The first area is information processing, which includes tasks like summarizing legal documents, translating text, redacting sensitive information, and e-discovery to find relevant documents for litigation. In this type of task, there is generally a clear correct answer (although there are exceptions), which makes it relatively straightforward to train, evaluate, and deploy AI.
For this reason, even before large language models, it was possible to train special-purpose models for each task. Legal tech, which is a mature industry, has long deployed automation and AI for information processing. As these products get revamped using large language models, there will likely be improvements in terms of accuracy and usability, but not fundamentally new capabilities nor a qualitative leap in accuracy. In other words, evolution, not a revolution.
The second area consists of tasks involving creativity, reasoning, or judgment. This includes preparing drafts of legal filings and even automated mediation and dispute resolution. In contrast to information processing, if AI could indeed automate such tasks, the impact on the legal profession might be huge. The paper reiterates and sharpens the reasons why we are doubtful that current AI is good enough to be useful here.
There is one important exception: spotting errors in legal filings. While this application does require a form of reasoning, it has many differences from, say, AI for preparing legal briefs:
-
It is a narrow setting: a custom model can be developed for a particular type of filing.
-
It has well-defined outcomes: either something is or isn’t an error (whereas what is a good legal argument is open to interpretation).
-
All the information needed for the task is present in the documents provided as input to the system.
The Social Security Administration already uses a simple model to spot errors in judgments on benefits claims. As a simple example, if an adjudicator denies an application that contains a medical claim without addressing that claim, the system will catch it. We point out in the paper that there are many other opportunities for deploying error-checking AI in the legal system.
The third area is AI for making predictions about the future. We’ve frequently written about the inherent limits of predictive AI and how it goes badly wrong, especially in criminal justice; the paper recaps those arguments.
There is one other major application of prediction in law, although it (fortunately) seems to be confined to the research world: predicting judges’ decisions before they happen. For more than 60 years, people seem to have thought that this capability is just around the corner.
Today there seem to be over 150 papers on the topic. It’s not entirely clear why one would want to predict court decisions; presumably, it could be useful to lawyers in guiding legal strategy or businesses to assess potential litigation risks. Most of the papers don’t seem to explain their motivation. It is sadly common in AI research to see papers where the task itself is just an excuse to throw machine learning at a dataset and write up the results.
Unfortunately, according to a review by Medvedeva and Mcbride, most of these papers aren’t doing prediction at all. They often use the judgment text containing the final judgment to ‘predict’ the verdict — a blatant example of leakage. Since the text of the final judgment includes the verdict, the model has access to the answer when making its prediction. Only 7% of papers actually predicted court decisions, and it is not clear that this can be done accurately enough to be useful.
Summary
The figure below summarizes the paper (click for a bigger version).
In the past, AI evaluation has relied on static, automated benchmarks. As AI starts to get more useful in the real world, this approach is breaking down, because the gap between benchmarks and deployment scenarios grows ever wider. What we need are socio-technical assessments carried out in the specific context in which the AI system would be deployed. In the past, this would have been summarily rejected as cost-prohibitive, but if AI developers want to make headway in consequential domains such as law, they must greatly increase the amount of time and resources devoted to evaluation.