
Among the innovations that power the popular open source TensorFlow machine learning platform are automatic differentiation (Autograd) and the XLA (Accelerated Linear Algebra) optimizing compiler for deep learning.
Google JAX is another project that brings together these two technologies, and it offers considerable benefits for speed and performance. When run on GPUs or TPUs, JAX can replace other programs that call NumPy, but its programs run much faster. Additionally, using JAX for neural networks can make adding new functionality much easier than expanding a larger framework like TensorFlow.
This article introduces Google JAX, including an overview of its benefits and limitations, installation instructions, and a first look at the Google JAX quickstart on Colab.
What is Autograd?
Autograd is an automatic differentiation engine that started out as a research project in Ryan Adams’ Harvard Intelligent Probabilistic Systems Group. As of this writing, the engine is being maintained but no longer actively developed. Instead, its developers are working on Google JAX, which combines Autograd with additional features such as XLA JIT compilation. The Autograd engine can automatically differentiate native Python and NumPy code. Its primary intended application is gradient-based optimization.
TensorFlow’s tf.GradientTape API is based on similar ideas to Autograd, but its implementation is not identical. Autograd is written entirely in Python and computes the gradient directly from the function, whereas TensorFlow’s gradient tape functionality is written in C++ with a thin Python wrapper. TensorFlow uses back-propagation to compute differences in loss, estimate the gradient of the loss, and predict the best next step.
What is XLA?
XLA is a domain-specific compiler for linear algebra developed by TensorFlow. According to the TensorFlow documentation, XLA can accelerate TensorFlow models with potentially no source code changes, improving speed and memory usage. One example is a 2020 Google BERT MLPerf benchmark submission, where 8 Volta V100 GPUs using XLA achieved a ~7x performance improvement and ~5x batch size improvement.
XLA compiles a TensorFlow graph into a sequence of computation kernels generated specifically for the given model. Because these kernels are unique to the model, they can exploit model-specific information for optimization. Within TensorFlow, XLA is also called the JIT (just-in-time) compiler. You can enable it with a flag in the @tf.function Python decorator, like so:
@tf.function(jit_compile=True)
You can also enable XLA in TensorFlow by setting the TF_XLA_FLAGS environment variable or by running the standalone tfcompile tool.
Apart from TensorFlow, XLA programs can be generated by:
Get started with Google JAX
I went through the JAX Quickstart on Colab, which uses a GPU by default. You can elect to use a TPU if you prefer, but monthly free TPU usage is limited. You also need to run a special initialization to use a Colab TPU for Google JAX.
To get to the quickstart, press the Open in Colab button at the top of the Parallel Evaluation in JAX documentation page. This will switch you to the live notebook environment. Then, drop down the Connect button in the notebook to connect to a hosted runtime.
Running the quickstart with a GPU made it clear how much JAX can accelerate matrix and linear algebra operations. Later in the notebook, I saw JIT-accelerated times measured in microseconds. When you read the code, much of it may jog your memory as expressing common functions used in deep learning.
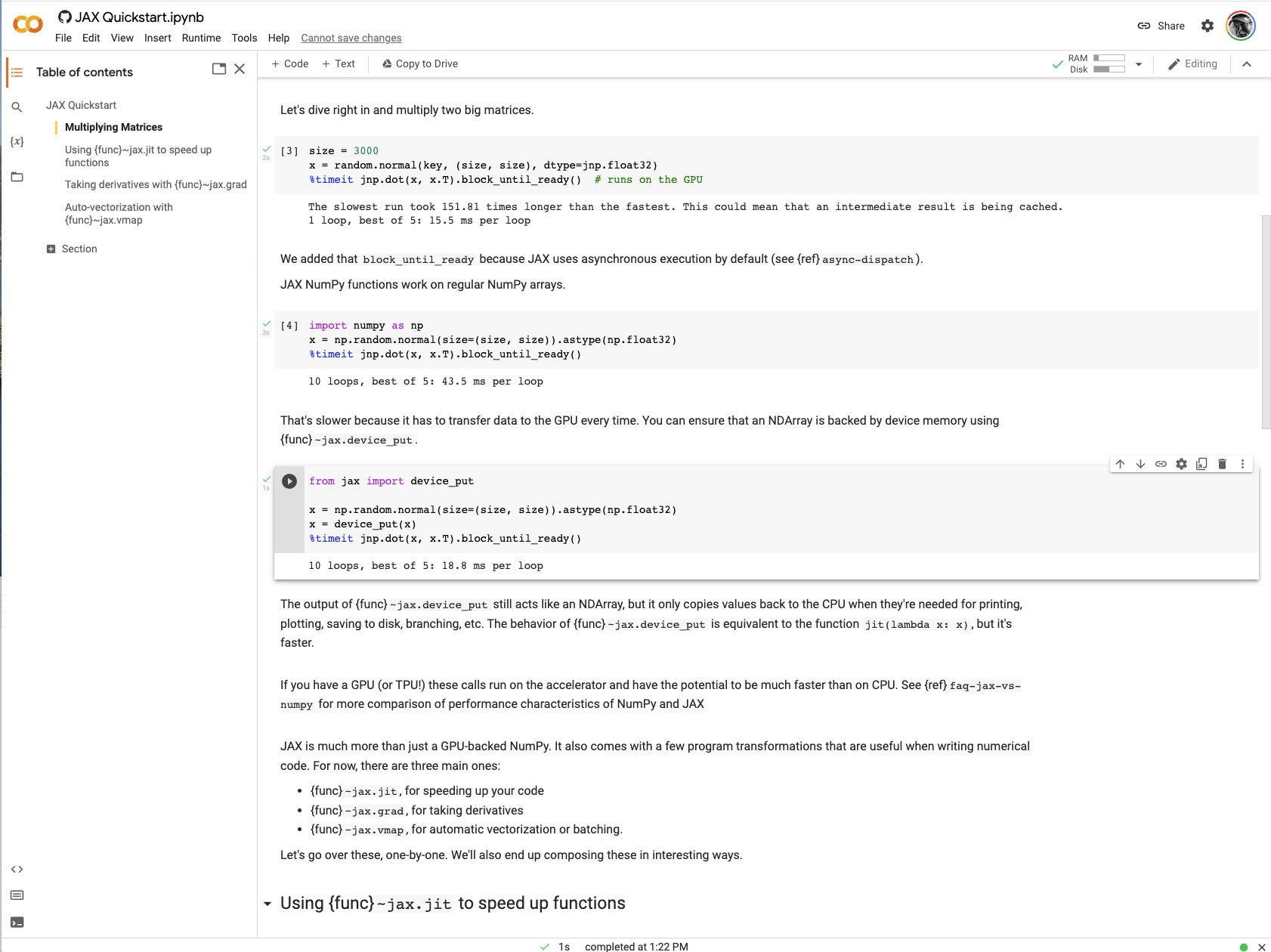 IDG
IDGFigure 1. A matrix math example in the Google JAX quickstart.
How to install JAX
A JAX installation must be matched to your operating system and choice of CPU, GPU, or TPU version. It’s simple for CPUs; for example, if you want to run JAX on your laptop, enter:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
For GPUs, you must have CUDA and CuDNN installed, along with a compatible NVIDIA driver. You’ll need fairly new versions of both. On Linux with recent versions of CUDA and CuDNN, you can install pre-built CUDA-compatible wheels; otherwise, you need to build from source.
JAX also provides pre-built wheels for Google Cloud TPUs. Cloud TPUs are newer than Colab TPUs and not backward compatible, but Colab environments already include JAX and the correct TPU support.
The JAX API
There are three layers to the JAX API. At the highest level, JAX implements a mirror of the NumPy API, jax.numpy. Almost anything that can be done with numpy can be done with jax.numpy. The limitation of jax.numpy is that, unlike NumPy arrays, JAX arrays are immutable, meaning that once created their contents cannot be changed.
The middle layer of the JAX API is jax.lax, which is stricter and often more powerful than the NumPy layer. All the operations in jax.numpy are eventually expressed in terms of functions defined in jax.lax. While jax.numpy will implicitly promote arguments to allow operations between mixed data types, jax.lax will not; instead, it supplies explicit promotion functions.
The lowest layer of the API is XLA. All jax.lax operations are Python wrappers for operations in XLA. Every JAX operation is eventually expressed in terms of these fundamental XLA operations, which is what enables JIT compilation.
Limitations of JAX
JAX transformations and compilation are designed to work only on Python functions that are functionally pure. If a function has a side effect, even something as simple as a print() statement, multiple runs through the code will have different side effects. A print() would print different things or nothing at all on later runs.
Other limitations of JAX include disallowing in-place mutations (because arrays are immutable). This limitation is mitigated by allowing out-of-place array updates:
updated_array = jax_array.at[1, :].set(1.0)
In addition, JAX defaults to single precision numbers (float32), while NumPy defaults to double precision (float64). If you really need double precision, you can set JAX to jax_enable_x64 mode. In general, single-precision calculations run faster and require less GPU memory.
Using JAX for accelerated neural networking
At this point, it should be clear that you could implement accelerated neural networks in JAX. On the other hand, why reinvent the wheel? Google Research groups and DeepMind have open-sourced several neural network libraries based on JAX: Flax is a fully featured library for neural network training with examples and how-to guides. Haiku is for neural network modules, Optax is for gradient processing and optimization, RLax is for RL (reinforcement learning) algorithms, and chex is for reliable code and testing.
Learn more about JAX
In addition to the JAX Quickstart, JAX has a series of tutorials that you can (and should) run on Colab. The first tutorial shows you how to use the jax.numpy functions, the grad and value_and_grad functions, and the @jit decorator. The next tutorial goes into more depth about JIT compilation. By the last tutorial, you are learning how to compile and automatically partition functions in both single and multi-host environments.
You can (and should) also read through the JAX reference documentation (starting with the FAQ) and run the advanced tutorials (starting with the Autodiff Cookbook) on Colab. Finally, you should read the API documentation, starting with the main JAX package.