
The announcements at GTC showcased covered both AI chips and models.

Next Week in The Sequence:
We do a summary of our series about RAG. The opinion edition discusses whether NVIDIA is the best VC in AI. The engineering installement explores a new AI framework. The research edition explores the amazing Search-R1 model.
You can subscribe to The Sequence below:
📝 Editorial: NVIDIA’s AI Hardware and Software Synergies are Getting Scary Good
NVIDIA’s GTC never disappoints. This year’s announcements covered everything from powerhouse GPUs to sleek open-source software, forming a two-pronged strategy that’s all about speed, scale, and smarter AI. With hardware like Blackwell Ultra and Rubin, and tools like Llama Nemotron and Dynamo, NVIDIA is rewriting what’s possible for AI development.
Let’s start with the hardware. The Blackwell Ultra AI Factory Platform is NVIDIA’s latest rack-scale beast, packing 72 Blackwell Ultra GPUs and 36 Grace CPUs. It’s 1.5x faster than the previous gen and tailor-made for agentic AI workloads—think AI agents doing real reasoning, not just autocomplete.
Then there’s the long game. Jensen Huang introduced the upcoming Rubin Ultra NVL576 platform, coming in late 2027, which will link up 576 Rubin GPUs using HBM4 memory and the next-gen NVLink interconnect. Before that, in late 2026, we’ll see the Vera Rubin NVL144 platform, with 144 Rubin GPUs and Vera CPUs hitting 3.6 exaflops of FP4 inference—over 3x faster than Blackwell Ultra. NVIDIA’s clearly gearing up for the huge compute demands of next-gen reasoning models like DeepSeek-R1.
On the software side, NVIDIA launched the Llama Nemotron family—open-source reasoning models designed to be way more accurate (20% better) and way faster (5x speed boost) than standard Llama models. Whether you’re building math solvers, code generators, or AI copilots, Nemotron comes in Nano, Super, and Ultra versions to fit different needs. Big names are already onboard. Microsoft’s integrating these models into Azure AI Foundry, and SAP’s adding them to its Joule copilot. These aren’t just nice-to-have tools—they’re key to building a workforce of AI agents that can actually solve problems on their own.
Enter Dynamo, NVIDIA’s new open-source inference framework. It’s all about squeezing maximum performance from your GPUs. With smart scheduling and separate prefill/decode stages, Dynamo helps Blackwell hardware handle up to 30x more requests, all while cutting latency and costs.
This is especially important for today’s large-scale reasoning models, which chew through tons of tokens per query. Dynamo makes sure all that GPU horsepower isn’t going to waste. While Blackwell is today’s star, the Rubin architecture is next in line. Launching late 2026, the Vera Rubin GPU and its 88-core Vera CPU are set to deliver 50 petaflops of inference—2.5x Blackwell’s output. Rubin Ultra scales that to 576 GPUs per rack.
Looking even further ahead, NVIDIA teased the Feynman architecture (arriving in 2028), which will take things up another notch with photonics-enhanced designs. With a new GPU family dropping every two years, NVIDIA’s not just moving fast—it’s setting the pace.
The real story here is synergy. Blackwell and Rubin bring the power. Nemotron and Dynamo help you use it smartly. This combo is exactly what enterprises need as they move toward AI factories—data centers built from the ground up for AI-driven workflows. GTC 2025 wasn’t just a product showcase—it was a blueprint for the next decade of AI. With open models like Nemotron, deployment tools like Dynamo, and next-gen platforms like Rubin and Feynman, NVIDIA’s making it easier than ever to build smart, scalable AI. The future of computing isn’t just fast—it’s intelligent. And NVIDIA’s making sure everyone—from startups to hyperscalers—has the tools to keep up.
🔎 AI Research
Synthetic Data and Differential Privacy
In the paper“Private prediction for large-scale synthetic text generation“ researchers from Google present an approach for generating differentially private synthetic text using large language models via private prediction. Their method achieves the generation of thousands of high-quality synthetic data points, a significant increase compared to previous work in this paradigm, through improvements in privacy analysis, private selection mechanisms, and a novel use of public predictions.
KBLAM
In the paper “KBLAM: KNOWLEDGE BASE AUGMENTED LANGUAGE MODEL” Microsoft Research propose KBLAM, a new method for augmenting large language models with external knowledge from a knowledge base. KBLAM transforms knowledge triples into continuous key-value vector pairs and integrates them into LLMs using a specialized rectangular attention mechanism, differing from RAG by not requiring a separate retrieval module and offering efficient scaling with the knowledge base size.
Search-R1
In the paper “Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning” researchers from the University of Illinois at Urbana-Champaign introduce SEARCH-R1, a novel reinforcement learning framework that enables large language models to interleave self-reasoning with real-time search engine interactions. This framework optimizes LLM rollouts with multi-turn search, utilizing retrieved token masking for stable RL training and a simple outcome-based reward function, demonstrating significant performance improvements on various question-answering datasets.
Cosmos-Reason1
In the paper“Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning” researchers from NVIDIA present Cosmos-Reason1, a family of multimodal large language models specialized in understanding and reasoning about the physical world. The development involved defining ontologies for physical common sense and embodied reasoning, creating corresponding benchmarks, and training models through vision pre-training, supervised fine-tuning, and reinforcement learning to enhance their capabilities in intuitive physics and embodied tasks.
Expert Race
This paper,“Expert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts”, presents additional results on the ImageNet 256×256 dataset by researchers who trained a Mixture of Experts (MoE) model called Expert Race, building upon the DiT architecture. The results show that their MoE model achieves better performance and faster convergence compared to a vanilla DiT model with a similar number of activated parameters, using a larger batch size and a specific training protocol.
RL in Small LLMs
In the paper “Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t” AI researchers investigate the use of reinforcement learning to improve reasoning in a small (1.5 billion parameter) language model under strict computational constraints. By adapting the GRPO algorithm and using a curated mathematical reasoning dataset, they demonstrated significant reasoning gains on benchmarks with minimal data and cost, highlighting the potential of RL for enhancing small LLMs in resource-limited environments.
📶AI Eval of the Weeek
(Courtesy of LayerLens )
Mistral Small 3.1 came out this week with some impressive results. The model seems very strong in programming benchmarks like Human Eval.
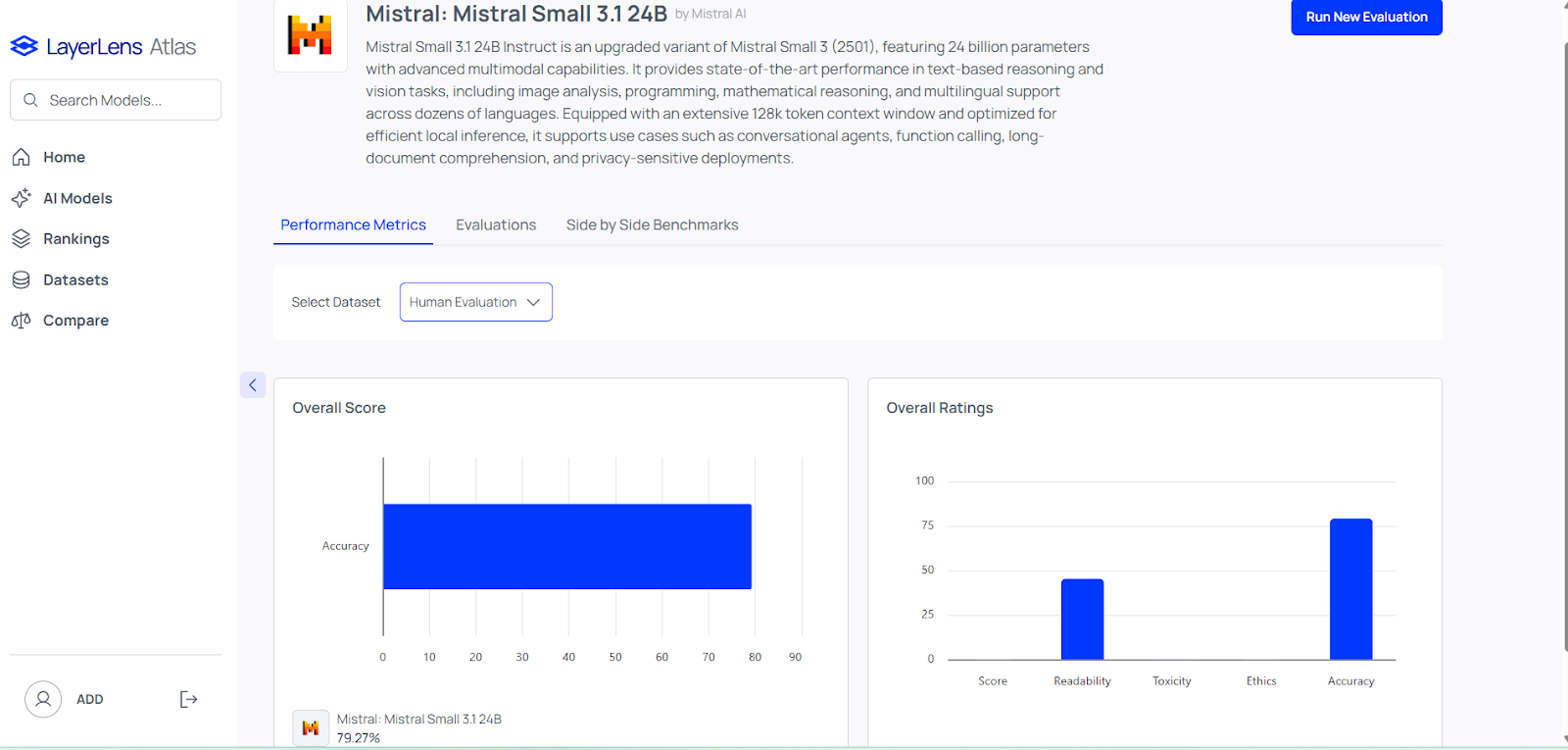
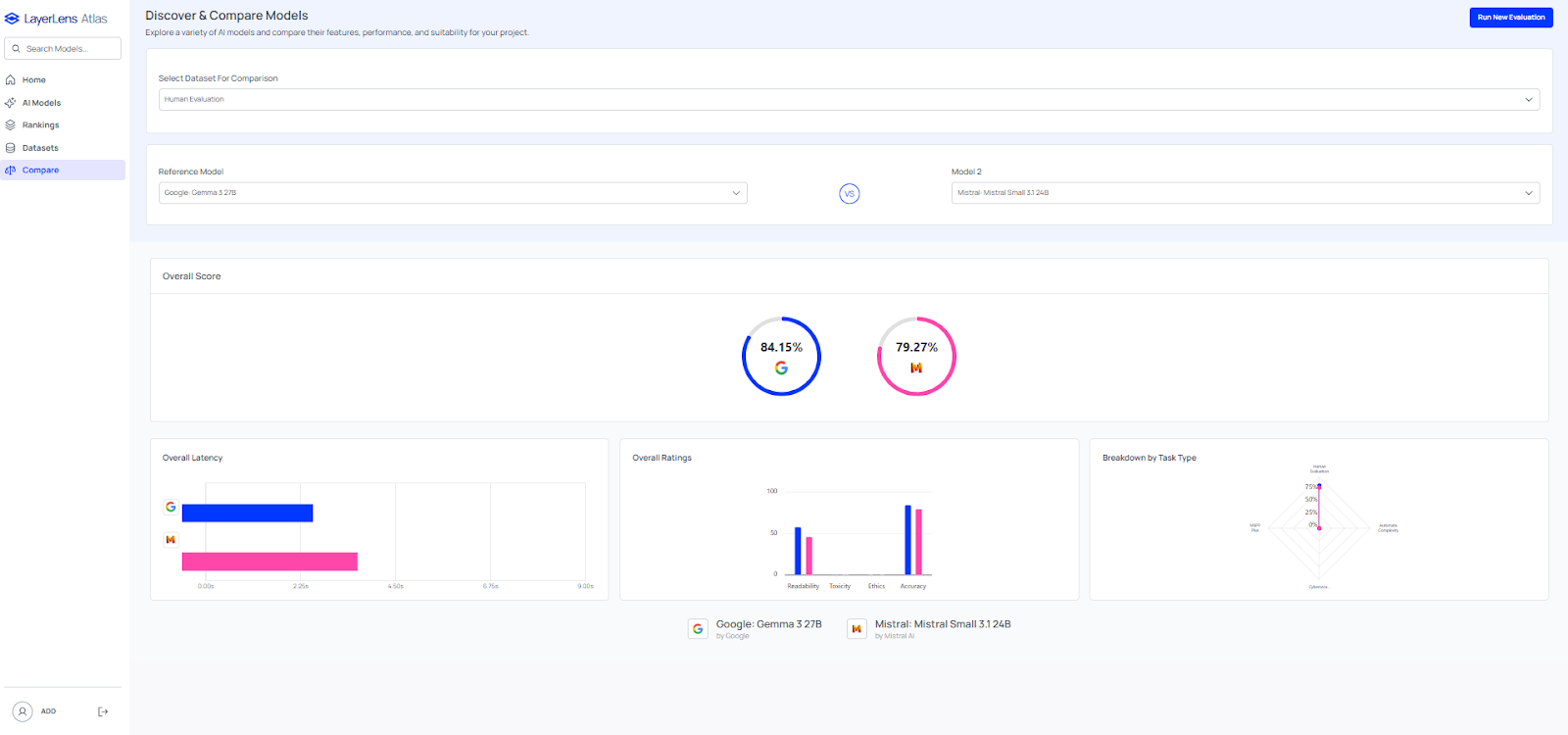
Mistral Small 3.1 also outperforms similar size models like Gemma 3.
🤖 AI Tech Releases
Claude Search
Anthropic added search capabilities to Claude.
Mistral Small 3.1
Mistral launched Small 3.1, a multimodal small model with impressive performance.
Model Optimization
Pruna AI open sourced its famout AI optimization framework.
📡AI Radar
-
Perplexity is raising a new round at $18 billion valuation.
-
SoftBank announced the acquisition of semiconductor platform Ampere Computing.
-
Data analytic company Dataminr raised $85 million in new funding.
-
AI security platform Orion Security emerged from stealth mode with $6 million in funding.
-
Roblox launched Roblox Cube, a new gen AI system for 3D and 4D assets.
-
Halliday blockchain-agentic platform raised $20 million in new funding.
-
ClearGrid raised $10 million to automated debt collection with AI.
-
Tera AI raised $7.8 million for its robotics navigation platform.
-
AI presentation platform Present raised $20 million in new funding.