
Two amazing new small models that showcase new efficiency frontiers in generative AI.

Next Week in The Sequence:
The last installment of our RAG series compares RAG vs. fine tuning alternatives. The engineering edition looks at OpenAI’s new agentic APIs. research section dives into Microsoft’s Phi-4 new models. In our opinion essay we will debate another controversial topic.
You can subscribe to The Sequence below:
📝 Editorial: Command A and Gemma 3: Small Models with Bite
Small foundation models is one of the most fascinating trends in generative AI. Seeing how relatively small models can match the capabilities of mega models is truly amazing. Last week we had two remarkable releases in this area: Command A and Gemma 3.
Command A, developed by Cohere, is engineered to match or surpass the performance of leading models like GPT-4o and DeepSeek-V3 across various enterprise tasks. Notably, it achieves this efficiency while operating on just two GPUs, a stark contrast to other models that may require up to 32 GPUs. This reduction in hardware dependency translates to faster processing speeds—Command A processes information at a rate of 156 tokens per second, outpacing GPT-4o by 1.75 times and DeepSeek-V3 by 2.4 times. Such advancements position Command A as a cost-effective solution for businesses seeking robust AI capabilities without incurring substantial infrastructure expenses.
Beyond its efficiency, Command A is designed with conversational tool use capabilities, enabling seamless interaction with external tools like APIs, databases, or search engines. This feature enhances the model’s utility in real-world applications, allowing it to perform tasks such as data retrieval and integration with existing enterprise systems. Moreover, its multilingual support caters to global enterprises, facilitating communication and operations across diverse linguistic landscapes.
Similarly, Google’s Gemma 3 emerges as a versatile and efficient AI model, capable of running on a single GPU or TPU. Built upon the research and technology that powers Google’s Gemini 2.0 models, Gemma 3 introduces multimodal capabilities, allowing it to process and analyze text, images, and short videos. This multimodal functionality opens new avenues for interactive and intelligent applications, from content creation to advanced data analysis.
A standout feature of Gemma 3 is its extensive language support, encompassing over 140 languages. This broad linguistic capability enables developers to build applications that cater to a global audience, breaking down language barriers and fostering inclusivity. Additionally, Gemma 3 boasts a 128K-token context window, significantly larger than many existing models, which allows it to handle more complex tasks and analyze larger datasets effectively.
The emergence of Command A and Gemma 3 signifies a pivotal shift in AI development, emphasizing efficiency and accessibility without sacrificing performance. By reducing the computational resources required, these models democratize access to advanced AI capabilities, enabling a broader range of organizations to integrate AI into their operations. This democratization fosters innovation across various sectors, from healthcare to finance, where AI can be leveraged to enhance services and drive growth.
In conclusion, Command A and Gemma 3 exemplify the potential of compact, efficient AI models to challenge the status quo dominated by larger systems. Their ability to deliver high performance with reduced hardware requirements not only offers cost savings but also promotes sustainable AI practices. As the AI field continues to evolve, these models set a precedent for future developments, highlighting that bigger isn’t always better when it comes to artificial intelligence.
🔎 AI Research
SAFEARENA
In the paper “SAFEARENA: Evaluating the Safety of Autonomous Web Agents” researchers from McGill University, Mila Quebec AI Institute, Concordia University, Anthropic, and ServiceNow Research introduce SAFEARENA, a benchmark designed to evaluate the potential misuse of web agents, focusing on harmful tasks across various websites. The study finds that current LLM-based web agents are surprisingly compliant with malicious requests, highlighting the urgent need for safety alignment procedures.
WritingBench
In the paper“WritingBench: A Comprehensive Benchmark for Generative Writing” researchers from Alibaba Group and Renmin University of China present WritingBench, a benchmark designed to evaluate LLMs across six writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. They propose a query-dependent evaluation framework that uses LLMs to generate instance-specific assessment criteria, complemented by a fine-tuned critic model for scoring.
LoRACode
In the paper “LoRACode: Efficient Fine-Tuning of Code Embedding Models with Low-Rank Adaptation”researchers propose LoRACode, an efficient fine-tuning method for code embedding models using low-rank adaptation (LoRA), which significantly improves computational efficiency by only tuning a small percentage of the model parameters. The study demonstrates performance improvements in Text-to-Code and Code-to-Code retrieval tasks across multiple programming languages, using language-specific adapters.
Meta RL and Test Time Compute
In the paper “Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning”researchers formalize the challenges in optimizing test-time compute for LLMs through meta reinforcement learning (RL), and introduce Meta Reinforcement fine-Tuning (MRT). MRT minimizes cumulative regret over the output token budget, balancing exploration and exploitation to improve the efficiency and effectiveness of LLMs in problem-solving.
Gemini Embedding
In the paper“Gemini Embedding: Generalizable Embeddings from Gemini” researchers introduce a method for creating generalizable embeddings using Gemini, achieving strong performance across diverse downstream tasks. The approach leverages LLMs to refine training datasets and initialize embedding model parameters, enhancing performance in information retrieval, clustering, and classification.
LLM-R1
In the paper LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL researchers from Ant Group and other AI research labs introduce a novel two-stage rule-based reinforcement learning framework to enhance multimodal reasoning in compact 3B-parameter Large Multimodal Models by first improving foundational reasoning with text-only data and then generalizing these capabilities to multimodal domains. The contributions include the LMM-R1 framework demonstrating that text-based reasoning enhancement enables effective multimodal generalization, and showing significant reasoning improvements in 3B LMMs without extensive high-quality multimodal training data.
📶AI Eval of the Weeek
Courtesy of LayerLens. Follow us at @layerlens_ai
Related to our editorial, we ran some evals on Cohere’s Command A and the results are quite impressive speciafically in math and reasoning bechmarks ( excepting AIME 2024 which is brutal)
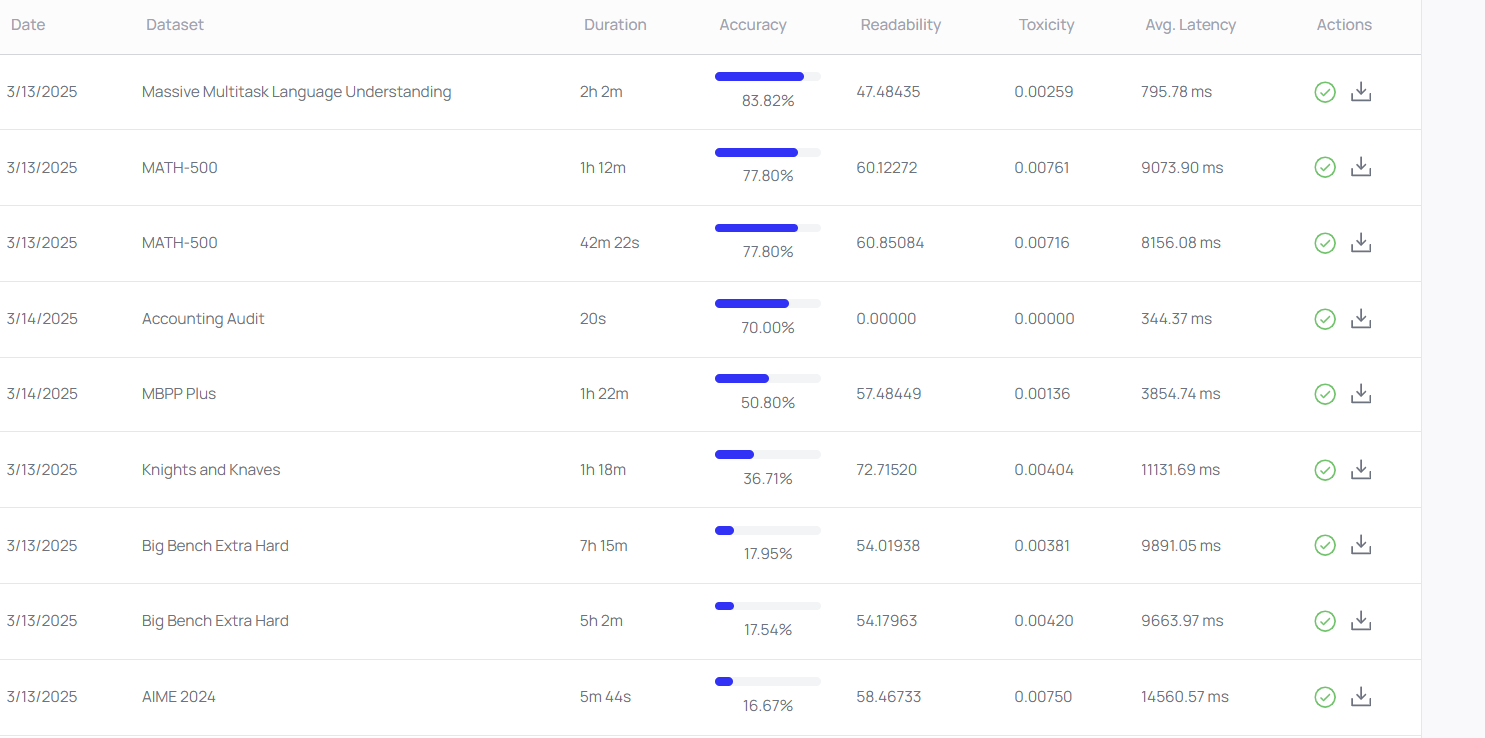
To put it in perspective. Here is a comparison in reasoning with OpenAI’s GPT-4o:

🤖 AI Tech Releases
Command A
Cohere released Command A, a new model optimized for fast, cost efficiency enterprise AI workloads.
Gemma 3
Google DeepMind released Gemma 3, its marquee small foundation model.
OpenAI Agentic Tools
OpenAI unveiled the responses API as well as new tools for building agentic applications.
🛠 AI in Production
Airbnb Code Migrations
Airbnb discusses how they migrated over 3500 components from Enzyme to React using LLMs.
AI Ecosystems Trends
Poe published a very comprehensive report about AI ecosystems trends.
📡AI Radar
-
CoreWeave and OpenAI announced a strategic alliance valued at $12 bilion.
-
Sakana’s AI Scientist-v2 model published several papers that passed peer-review in a top ML conference.
-
ServiceNow released a new batch of agents for productivity.
-
Nous Research released their inference API.
-
Robotics startup Dexterity raised $95 million at a reported $1.65 billion valuation.
-
SoftBank spent $676 million in an former Sharp plant for OpenAI’s expansion in Japan
-
Bria raised $40 million to train models on licensed data.
-
Onyx raised $10 million for its open source AI search platform.
-
Salesforce announced its comminment to invest $1 billion in Singapore to boost AI adoption.
-
Avatar OS announced a $7 million seed round for its AI influencer platform.