
As artificial intelligence (AI) continues to permeate various industries, the demand for efficient and powerful AI inference has surged. AI inference, the process of running trained machine learning models to make predictions or decisions, is computationally intensive and often constrained by the performance of the underlying hardware.
Enter hardware accelerators[1]—specialized hardware designed to optimize AI inference, providing significant improvements in flexibility, performance, and iteration time.
AI inference is the process of applying a trained machine learning model to new data in order to make predictions or decisions. With the growing demand for AI applications across industries, achieving real-time performance during inference is crucial.
Hardware accelerators, such as GPUs (Graphics Processing Units), NPUs (Neural Processing Units), FPGAs (Field-Programmable Gate Arrays), and ASICs (Application-Specific Integrated Circuits) play a significant role in enhancing AI inference performance by providing optimized computational power and parallelism.
This article explores the different types of hardware accelerators, their architecture, and how they can be leveraged to improve AI inference performance. This article explores how hardware accelerators enhance AI inference and the impact they have on modern AI applications.
AI Inference challenges
AI inference typically involves performing a large number of mathematical operations, such as matrix multiplications, which are computationally intensive.
Traditional CPUs, although powerful, are not optimized for these specific types of workloads, leading to inefficiencies in power consumption and speed. As AI models become more complex and data sets larger, the need for specialized hardware to accelerate inference has become apparent.
In AI inference, the balance between compute power and memory bandwidth is critical for optimal performance. Compute Power refers to the processing capability of the hardware, which handles the mathematical operations required by the AI model.
High compute power allows for faster processing of complex models. Memory Bandwidth is the speed at which data can be transferred between memory and the processing units. The computational requirements for training state-of-the-art Convolutional Neural Networks (CNNs) and Transformer models have been growing exponentially.
This trend has fueled the development of AI accelerators designed to boost the peak computational power of hardware. These accelerators are also being developed to address the diverse memory and bandwidth bottlenecks associated with AI workloads, particularly in light of the fact that DRAM memory scaling is lagging behind advancements in compute power as shown in Fig 1.
![Fig 1. Comparing the evolution of # parameters of CNN/Transformer models vs the Single GPU Memory [6]](https://lh7-rt.googleusercontent.com/docsz/AD_4nXf6LgiWUVMg2tEEE6MkUTcFyE8AWHgMA3i7Kr5ATZm3orrOyZkbynC1pvA9iKHaCB5y0BP4P88qU1IGgabB4uHxrdISMZz4F8J67pIu41HnArbhsOOh09Gr3xPgB2Q5yxCwzqna6QG-VX6dSgM-iUueic0?key=JHuFRCJWX6JzcjI4cfHjEQ)
Fig 1. Comparing the evolution of # parameters of CNN/Transformer models vs the Single GPU Memory [6]
![Fig 2. Computer (FLOPs) vs Memory Bandwidth (/Inference) for different CNN architectures [7]](https://lh7-rt.googleusercontent.com/docsz/AD_4nXfXC4IMr2SNjQyhxPXMpQoc3noMaM24Gmb8CukA65oBAxtiJGdpu_S88suhkC4V-k_FufiFO1-pj_66qF_FbBJmwzUpBTfYNv138dRoDxNRqbxVEjr7nCMdUPVxZex8vjssAdb-uvjESrlEjo4hfS94w7w?key=JHuFRCJWX6JzcjI4cfHjEQ)
Fig 2. Computer (FLOPs) vs Memory Bandwidth (/Inference) for different CNN architectures [7]
Fig 2 and 3, shows the computer vs memory bandwidth of the popular AI models[6-7]. Even with high compute power, if memory bandwidth is insufficient, the processors may spend time waiting for data, leading to underutilization of compute resources. Ensuring that memory bandwidth matches the compute demands of the AI model is essential for avoiding bottlenecks and maximizing inference performance.
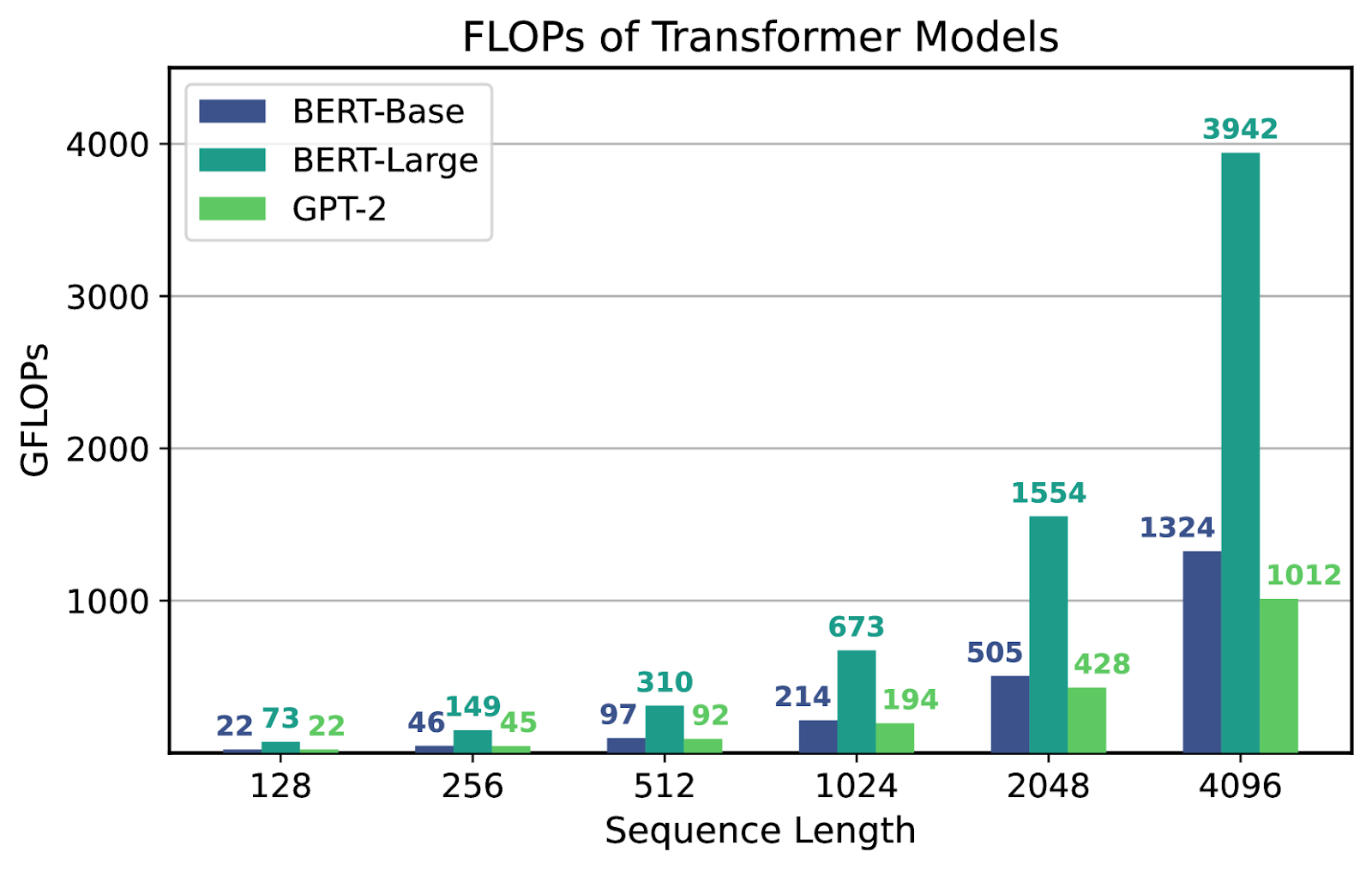
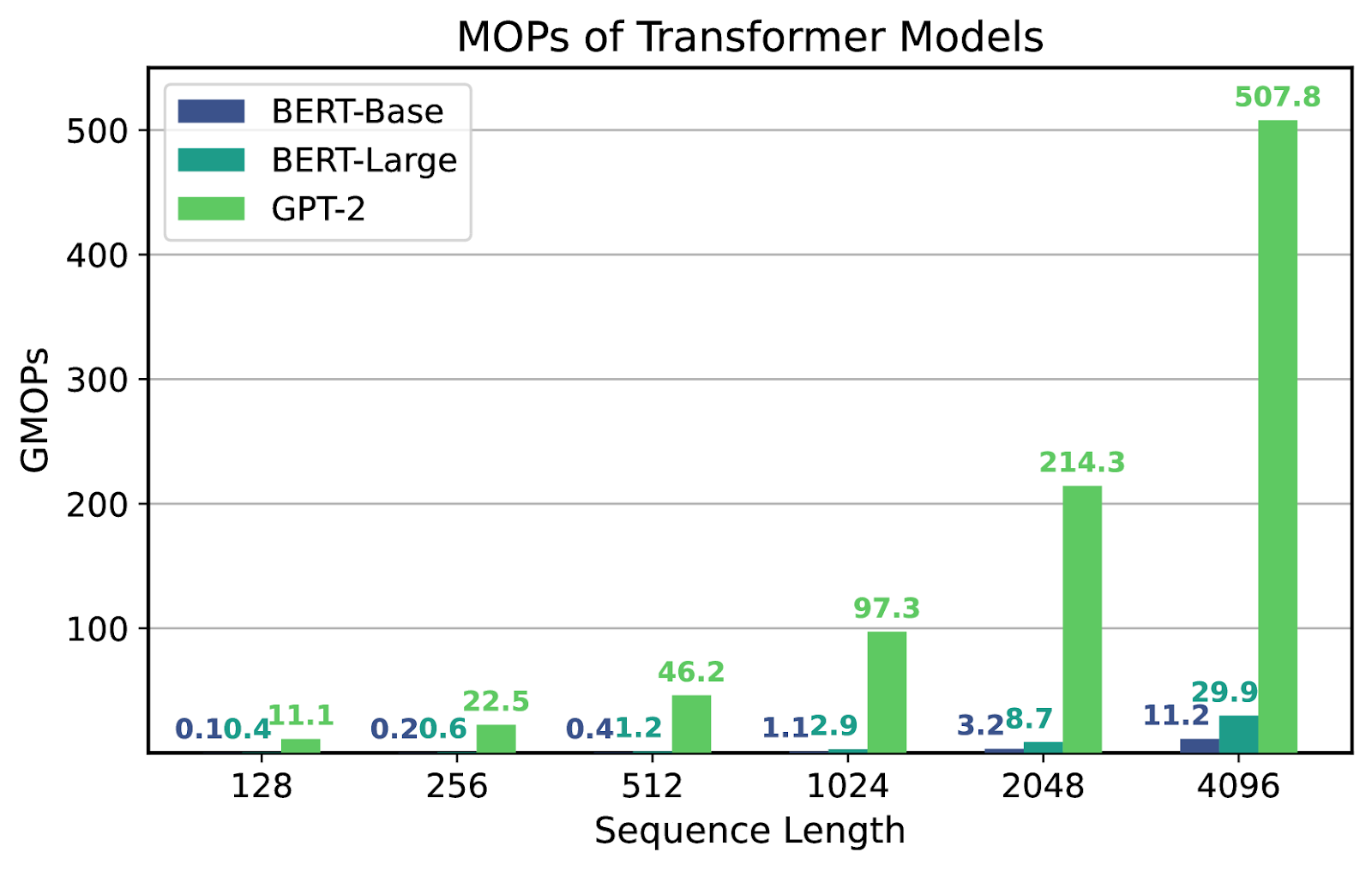
Fig 3. Compute (FLOPs) vs Arithmetic Intensity (MOPs) for different Transformer (LLM) Models [6]
Hardware accelerators
Hardware accelerators, such as GPUs, NPUs, FPGAs, and ASICs, offer a range of deployment options that cater to diverse AI applications. These accelerators can be deployed on-premises, in data centers, or at the edge, providing flexibility to meet specific needs and constraints.
The primary advantage of hardware accelerators is their ability to significantly boost computational performance. GPUs, with their parallel processing capabilities, excel at handling the massive matrix operations typical in AI inference. This parallelism allows for faster processing of large datasets and complex models, reducing the time required to generate predictions.
NPUs, specifically designed for AI workloads, offer even greater performance improvements for certain deep learning tasks. By optimizing the hardware for matrix multiplications and convolutions, NPUs can deliver superior throughput and efficiency compared to general-purpose processors. The architecture of hardware accelerators plays a crucial role in their ability to enhance AI inference performance.
Below, we outline the key architectural features of GPUs, NPUs, FPGAs, and ASICs.
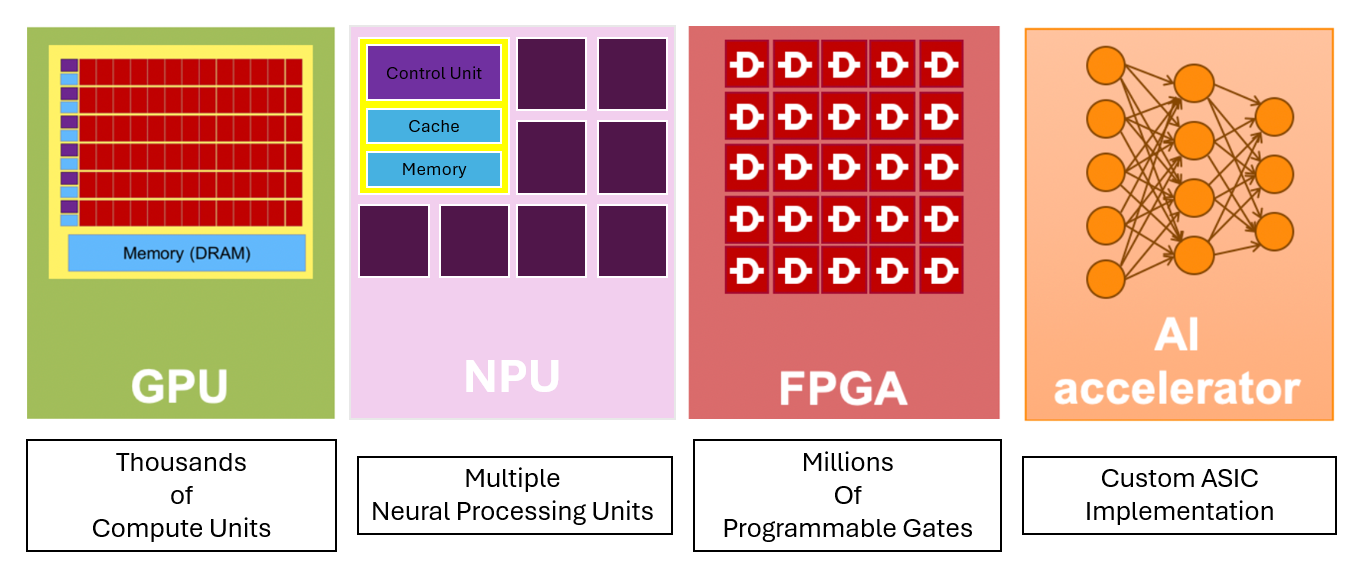
Fig 4. Overview of Hardware architecture for Hardware Accelerators
Graphics Processing Units (GPUs)
GPUs are widely used for AI workloads due to their ability to perform parallel computations efficiently. Unlike CPUs, which are optimized for sequential tasks, GPUs can handle thousands of parallel threads, making them ideal for the matrix and vector operations common in deep learning.
The GPU architecture is designed with thousands of computer units along with scratch memory and control units, enabling highly parallel data processing. Modern GPUs, such as NVIDIA’s A100, are specifically designed for AI workloads, offering features like tensor cores that provide further acceleration for AI operations.
The architecture of a GPU consists of multiple cores, each capable of executing thousands of threads simultaneously. Modern GPUs include specialized cores, such as tensor cores, which are designed specifically for deep learning operations. The memory bandwidth and large register files of GPUs enable efficient handling of large datasets.
Neural Processing Units (NPUs)
NPUs are custom accelerators designed specifically for neural network processing. NPUs are optimized for inference tasks, and they excel at handling large-scale AI models.
The architecture of NPUs contains multiple compute units that allow them to perform matrix multiplications and convolutions more efficiently than GPUs, particularly for models like convolutional neural networks (CNNs).
The architecture of an NPU allows for the efficient execution of matrix multiplications. NPUs include on-chip memory to reduce data transfer times and increase throughput. The array architecture is particularly effective for CNNs and other deep learning models.
Field-Programmable Gate Arrays (FPGAs)
FPGAs offer a unique advantage due to their reconfigurability. They contain millions of programmable gates that can be programmed to optimize specific tasks, such as AI inference, by tailoring the hardware to the specific needs of the application.
This makes FPGAs highly efficient for AI workloads, especially in scenarios where low latency is critical, such as in real-time systems. Companies like Xilinx and Intel offer FPGAs that can be configured to accelerate AI inference.
FPGAs are composed of a grid of configurable logic blocks connected by programmable interconnects. The flexibility of FPGAs allows them to be customized for specific AI workloads, optimizing both performance and power consumption. The ability to reprogram the logic blocks enables FPGAs to adapt to different neural network models as needed.
Application-Specific Integrated Circuits (ASICs)
ASICs are custom-designed chips optimized for a specific application or task. In the context of AI, ASICs are designed to accelerate specific neural network models. An example is Google’s Edge TPU, which is designed for fast and efficient AI inference on edge devices.
The main advantage of ASICs is their efficiency in terms of both power consumption and performance, but they lack the flexibility of FPGAs. ASICs are highly optimized for specific tasks, with a fixed architecture that is designed to maximize efficiency for those tasks.
In the case of AI inference, ASICs are designed to execute specific neural network models with minimal power consumption and maximum speed. This fixed architecture, while highly efficient, lacks the flexibility of FPGAs.
Optimization techniques
To fully leverage the capabilities of various hardware accelerators, different optimization techniques can be applied, each tailored to the strengths of specific hardware types:
Network Architecture Search (NAS): NAS is particularly valuable for customizing neural network architectures to suit specific hardware accelerators. For edge devices, NAS can craft lightweight models that minimize parameters while maximizing performance.
This is especially crucial for NPUs and ASICs, where designing architectures that efficiently utilize hardware resources is essential for optimizing performance and energy efficiency.
Quantization: Quantization involves reducing the precision of a model’s weights and activations, typically from floating-point to fixed-point representations. This technique is highly effective on NPUs, ASICs, and FPGAs, where lower precision computations can drastically improve inference speed and reduce power consumption.
GPUs also benefit from quantization, though the gains may be less pronounced compared to specialized hardware like NPUs and ASICs.
Pruning: Pruning reduces the number of unnecessary weights in a neural network, thereby decreasing the computational load and enabling faster inference. This technique is particularly effective for FPGAs and ASICs, which benefit from reduced model complexity due to their fixed or reconfigurable resources.
Pruning can also be applied to GPUs and NPUs, but the impact is most significant in environments where hardware resources are tightly constrained.
Kernel fusion: Kernel fusion combines multiple operations into a single computational kernel, reducing the overhead of memory access and improving computational efficiency.
This optimization is especially beneficial for GPUs and NPUs, where reducing the number of memory-bound operations can lead to significant performance improvements. Kernel fusion is less applicable to FPGAs and ASICs, where operations are often already highly optimized and customized.
Memory optimization: Optimizing memory access patterns and minimizing memory footprint are critical for maximizing the available bandwidth on hardware accelerators.
For GPUs, efficient memory management is key to improving throughput, particularly in large-scale models. NPUs also benefit from memory optimization, as it allows for more efficient execution of neural networks. FPGAs and ASICs, with their specialized memory hierarchies, require careful memory planning to ensure that data is efficiently accessed and processed, thereby enhancing overall inference performance.
AI model deployment challenges
Deploying AI models on hardware accelerators presents several challenges, particularly in terms of flexibility, iteration time, and performance. Each type of accelerator—GPUs, NPUs, FPGAs, and ASICs—poses unique considerations in these areas.
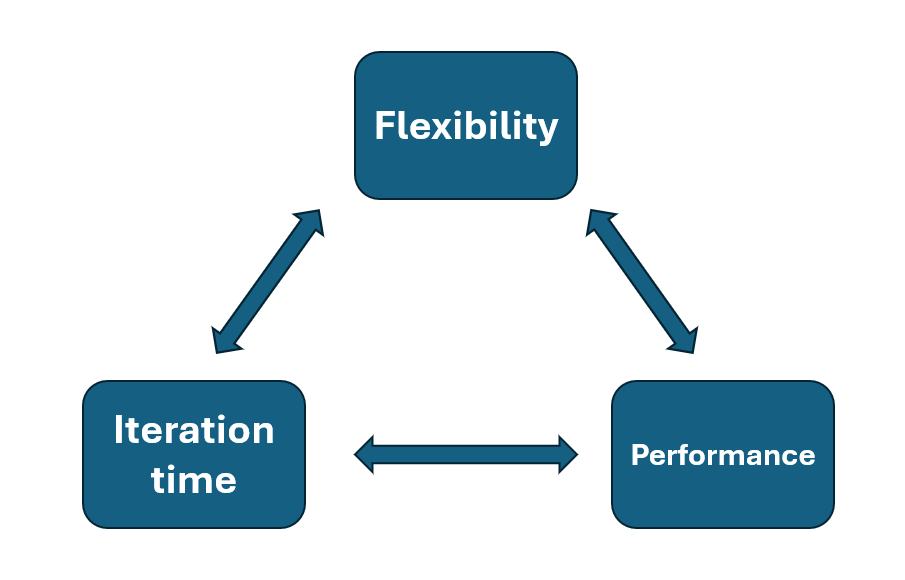
Fig 5. Different trade-offs AI Model deployment on accelerators
Flexibility: Flexibility is vital for supporting the latest AI models and adapting to evolving frameworks. GPUs, with their general-purpose architecture, offer the highest flexibility among accelerators, making them well-suited for rapidly integrating new models and frameworks.
NPUs, while more specialized, also provide a good balance of flexibility, particularly for neural network tasks, though they may require some adjustments for new operations or model types.
FPGAs are reconfigurable, allowing for custom adjustments to support new models, but this reconfiguration can be complex and time-consuming. ASICs, being custom-designed for specific tasks, offer the least flexibility; any change in model architecture or framework may require a new chip design, which is costly and time-intensive.
The challenge, therefore, lies in ensuring that the deployment environment can integrate advancements without extensive reconfiguration, especially in less flexible hardware like ASICs and FPGAs.
Iteration time: Iteration time, or the speed at which improved AI models can be deployed, is crucial for maintaining the effectiveness of AI systems. GPUs excel in this area due to their compatibility with a wide range of development tools and frameworks, allowing for faster model optimization and deployment.
NPUs also support relatively quick iteration times, especially when deploying models tailored for neural network tasks. However, the application of optimization techniques like quantization and pruning can add complexity, requiring thorough validation to ensure that the model meets performance and key performance indicators (KPIs) post-deployment.
FPGAs, though powerful, often have longer iteration times due to the need for reconfiguration and hardware-specific optimization. ASICs present the greatest challenge in iteration time, as any update or improvement to the model could necessitate redesigning the hardware, which is a slow and expensive process.
Performance: Performance is a key concern when deploying AI models on hardware accelerators. For GPUs, achieving optimal performance involves maximizing hardware resource utilization and efficiently scaling across multiple units, which can be managed relatively easily due to the mature ecosystem of tools available.
NPUs, designed specifically for AI workloads, generally achieve high performance with low latency and high throughput but may require fine-tuning to fully leverage their capabilities. FPGAs, with their customizability, can achieve exceptional performance for specific tasks but often require manual tuning, including custom kernel development and modifications to fully optimize the model.
ASICs deliver the best performance per watt for specific tasks due to their tailored design, but achieving this performance involves significant upfront design work, and any deviation from the initial model can severely impact performance.
These challenges underscore the importance of a carefully considered deployment strategy tailored to the specific hardware accelerator being used. By understanding and addressing the unique flexibility, iteration time, and performance challenges of GPUs, NPUs, FPGAs, and ASICs, organizations can fully leverage the potential of hardware accelerators for AI model deployment.
Performance comparison
When evaluating the performance of various hardware accelerators, it is crucial to consider several key factors, including throughput, latency, power consumption, scalability, and cost. Below is an updated summary of these performance metrics for GPUs, NPUs, FPGAs, and ASICs.
Throughput: GPUs are known for their high throughput, making them ideal for large-scale AI models and batch-processing tasks. NPUs, designed specifically for AI workloads, also offer high throughput but are optimized for neural network processing. FPGAs and ASICs, while capable of high throughput, are typically employed in scenarios where low latency is more critical than raw throughput.
Latency: FPGAs and ASICs generally offer lower latency compared to GPUs and NPUs, making them well-suited for real-time applications. FPGAs are particularly valuable because of their reconfigurability, allowing them to be tailored for low-latency inference tasks. ASICs, being custom-designed for specific tasks, are also optimized for minimal latency.
Power Consumption: In terms of energy efficiency, ASICs are the most power-efficient due to their specialized design. NPUs, which are also designed for AI tasks, offer better energy efficiency compared to general-purpose GPUs.
FPGAs tend to consume more power than ASICs but are generally more power-efficient than GPUs, especially when configured for specific tasks. GPUs, while offering high performance, are typically less power-efficient, but their use can be justified in scenarios where their computational power is necessary.
Scalability: All four types of accelerators offer scalability, but the approaches differ. GPUs are widely used in data centers, where multiple units can be deployed in parallel to manage large-scale AI workloads. NPUs, with their specialized architecture, also scale well in distributed AI environments.
FPGAs provide flexibility and can be reconfigured to scale with the workload, while ASICs, though less flexible, offer scalable solutions when deployed in specific applications. Cloud providers often offer accelerator instances, allowing organizations to dynamically scale their AI infrastructure according to workload requirements.
Cost: ASICs are the most expensive to design and manufacture due to their custom nature, which requires significant upfront investment. FPGAs are more cost-effective for applications that require flexibility and reconfigurability.
GPUs, being general-purpose processors, are typically more affordable for a wide range of AI workloads, making them a popular choice for many applications. NPUs, though specialized, generally fall between GPUs and ASICs in terms of cost, offering a balance of efficiency and affordability depending on the use case.
Future trends
The future of AI inference hardware accelerators is poised for significant advancements, driven by the need for more specialized, efficient, and scalable architectures. Several emerging trends are shaping the development of next-generation hardware accelerators:
Heterogeneous computing: The future of AI hardware will likely involve a heterogeneous approach, combining multiple types of processors—such as CPUs, GPUs, NPUs, FPGAs, and ASICs—into a single system to leverage the strengths of each.
This approach allows for the dynamic allocation of workloads to the most appropriate hardware, optimizing performance, power consumption, and efficiency. Heterogeneous computing architectures are expected to become more prevalent as AI models continue to grow in complexity, requiring diverse hardware capabilities to meet different computational demands.
Innovations in software frameworks and tools will be critical to managing these complex systems and ensuring seamless integration between different types of accelerators.
Neuromorphic computing is an innovative approach inspired by the human brain’s architecture. Neuromorphic chips are designed to mimic the structure and function of biological neural networks, enabling AI inference with remarkably low power consumption and high efficiency.
These chips use spiking neural networks (SNNs), which process information in a way that resembles how neurons communicate in the brain—through spikes of electrical activity.
This approach can dramatically reduce energy usage compared to traditional digital processors, making neuromorphic chips ideal for battery-powered devices and other energy-constrained environments. Companies like Intel (with its Loihi chip) and IBM (with its TrueNorth chip) are leading the development of neuromorphic computing, aiming to bring brain-inspired computing closer to practical applications.
3D chip stacking, also known as 3D integration, is an emerging technology that involves stacking multiple layers of semiconductor chips vertically to create a single, densely packed unit.
This technique allows for greater integration of processing, memory, and communication resources, leading to significant improvements in performance, power efficiency, and form factor.
By reducing the distance that data needs to travel between different parts of the chip, 3D stacking can greatly reduce latency and increase bandwidth, making it a promising solution for AI inference tasks that require high throughput and low latency. The technology also enables more compact designs, which are essential for advanced AI applications in portable devices and edge computing.
Edge AI refers to the deployment of AI models directly on devices at the edge of the network, rather than relying on centralized cloud computing. As the demand for real-time processing in IoT devices, autonomous vehicles, and mobile applications continues to grow, edge AI is becoming increasingly important.
Specialized accelerators like Google’s Edge TPU are designed specifically for low-power AI inference on edge devices, enabling fast and efficient processing close to where data is generated.
These accelerators are optimized for tasks such as image recognition, natural language processing, and sensor data analysis, allowing for real-time AI applications without the need for constant connectivity to the cloud. The growth of edge AI is also driving innovations in energy-efficient hardware design, making it possible to deploy powerful AI capabilities in small, power-constrained devices .
Quantum computing for AI: Although still in its early stages, quantum computing holds the potential to revolutionize AI inference by leveraging quantum mechanics to perform computations at unprecedented speeds.
Quantum computers could solve certain types of problems much faster than classical computers, including those involving optimization, search, and sampling, which are common in AI.
While quantum hardware is not yet ready for widespread AI inference tasks, ongoing research and development suggest that quantum accelerators could eventually complement traditional hardware by handling specific, highly complex AI computations that are beyond the reach of current digital systems.
These trends indicate that the future of AI inference hardware will be marked by increasingly specialized and efficient architectures, tailored to meet the growing demands of AI applications across various domains.
By embracing these emerging technologies, the industry will be able to push the boundaries of what is possible in AI, driving new innovations and unlocking new possibilities for real-time, energy-efficient AI processing.
Conclusion
Hardware accelerators are revolutionizing AI inference by enhancing flexibility, performance, and iteration time. Their versatile deployment options, adaptability to different workloads, and future-proofing capabilities make them indispensable in modern AI infrastructure.
By delivering accelerated computation, improved energy efficiency, and scalability, hardware accelerators ensure that AI applications can meet the demands of today’s data-intensive and real-time environments. Furthermore, by reducing iteration time, they enable faster model development, real-time inference, and rapid prototyping, driving innovation and competitiveness in the AI landscape.
As AI continues to evolve, the role of hardware accelerators will only become more pivotal, unlocking new possibilities and transforming industries across the board. Hardware accelerators are essential for improving AI inference performance, enabling faster and more efficient processing of complex models.
By understanding the capabilities and limitations of different types of accelerators, such as GPUs, NPUs, FPGAs, and ASICs, developers can choose the right hardware for their specific AI applications. As the field continues to evolve, we can expect to see further innovations in accelerator technology, driving the next wave of AI advancements.
References
[1] Mittal, S. (2020). “A Survey on Accelerator Architectures for Deep Neural Networks.” Journal of Systems Architecture, 99, 101635. DOI: 10.1016/j.sysarc.2019.101635.
[2] Li, C., et al. (2016). “FPGA Acceleration of Recurrent Neural Network Based Language Model.” *ACM Transactions on Reconfigurable Technology and Systems (TRETS)*.
[3] NVIDIA Corporation. (2020). “NVIDIA A100 Tensor Core GPU Architecture.”
[4] Xilinx Inc. (2019). “Versal AI Core Series: Datasheet.”
[5] Sze, V., et al. (2017). “Efficient Processing of Deep Neural Networks: A Tutorial and Survey.” Proceedings of the IEEE.
[6] Gholami, A., Yao, Z., Kim, S., Hooper, C., Mahoney, M. W., and Keutzer, K. Ai and memory wall. IEEE Micro, pp. 1–5, 2024.
[7] Dwith Chenna, Evolution of Convolutional Neural Network(CNN): Compute vs Memory bandwidth for Edge AI, IEEE FeedForward Magazine 2(3), 2023, pp. 3-13.
Wondering what aspects of hardware are more important for computer vision?
Have a read below:
5 components of computer vision hardware you need to know
In this article, we cover a few components of hardware you need to know to work with computer vision.
