Collaboration with NVIDIA boosts Milvus performance 50x
Last week, Zilliz and NVIDIA collaborated to unveil Milvus 2.4 – the world’s first vector database accelerated by powerful GPU indexing and search capabilities. This breakthrough release harnesses NVIDIA GPUs’ massively parallel computing power and the new CUDA-Accelerated Graph Index for Vector Retrieval (CAGRA) from the RAPIDS cuVS library.
The performance gains enabled by GPU acceleration in Milvus 2.4 are extraordinary. Benchmarks demonstrate up to 50x faster vector search performance than industry standard CPU-based indexes like HNSW.
While the open-source Milvus 2.4 is available now, enterprises looking for a fully managed vector database service can look forward to GPU acceleration coming to Zilliz Cloud later this year. Zilliz Cloud provides a seamless experience for deploying and scaling Milvus on major cloud providers like AWS, GCP, and Azure without operational overhead.
We asked Charles Xie, the founder and CEO of Zilliz, to tell us more about it.
What is Milvus
Milvus is an open-source vector database system built for large-scale vector similarity search and AI workloads. Initially created by Zilliz, an innovator in the realm of unstructured data management and vector database technology, Milvus made its debut in 2019. To encourage widespread community engagement and adoption, it has been hosted by the Linux Foundation since 2020.
Since its inception, Milvus has gained considerable traction within the open-source ecosystem. With over 26,000 stars and over 260 contributors on GitHub and a staggering 20 million+ downloads and installations worldwide, it has become one of the most widely adopted vector databases globally. Milvus is trusted by over 5,000 enterprises across diverse industries, including AIGC, e-commerce, media, finance, telecom, and healthcare, to power their mission-critical vector search and AI applications at scale.
Why GPU Acceleration
In today’s data-driven world, quickly and accurately searching through vast amounts of unstructured data is crucial for powering cutting-edge AI applications. From generative AI and similarity search to recommendation engines and virtual drug discovery, vector databases have emerged as the backbone technology enabling these advanced capabilities. However, the insatiable demand for real-time indexing and high throughput has continued to push the boundaries of what’s possible with traditional CPU-based solutions.
Real-time indexing
Vector databases often need to ingest and index new vector data continuously and at a high velocity. Real-time indexing capabilities are essential to keep the database up-to-date with the latest data without creating bottlenecks or backlogs.
High throughput
Many applications that leverage vector databases, such as recommendation systems, semantic search engines, and anomaly detection, require real-time or near-real-time query processing. High throughput ensures that vector databases can handle a large volume of incoming queries concurrently, delivering low-latency responses to end-users or services.
At the heart of vector databases lies a core set of vector operations, such as similarity calculations and matrix operations, which are highly parallelizable and computationally intensive. With their massively parallel architecture comprising thousands of cores capable of executing numerous threads simultaneously, GPUs are an ideal computational engine for accelerating these operations.
The Architecture
To address these challenges, NVIDIA developed CAGRA, a GPU-accelerated framework that leverages the high-performance capabilities of GPUs to deliver exceptional throughput for vector database workloads. Next, let’s explore how to integrate the CAGRA algorithm into the Milvus system.
Milvus is designed for cloud-native environments and follows a modular design philosophy. It separates the system into various components and layers involved in handling client requests, processing data, and managing the storage and retrieval of vector data. Thanks to this modular design, Milvus can update or upgrade the implementation of specific modules without changing their interfaces. This modularity makes it relatively easy to incorporate GPU acceleration support into Milvus.

The modular architecture of Milvus comprises components such as the Coordinator, Access Layer, Message Queue, Worker Node, and Storage layers. The Worker Node itself is further subdivided into Data Nodes, Query Nodes, and Index Nodes. The Index Nodes are responsible for building indexes, while the Query Nodes handle query execution.
To leverage the benefits of GPU acceleration, CAGRA is integrated into Milvus’ Index and Query Nodes. This integration enables offloading computationally intensive tasks, such as index building and query processing, to GPUs, taking advantage of their parallel processing capabilities.
Within the Index Nodes, CAGRA support has been incorporated into the index building algorithms, allowing for efficient construction and management of high-dimensional vector indexes on GPU hardware. This acceleration significantly reduces the time and resources required for indexing large-scale vector datasets.
Similarly, in the Query Nodes, CAGRA is utilized to accelerate the execution of complex vector similarity searches. By leveraging GPU processing power, Milvus can perform high-dimensional distance calculations and similarity searches at unprecedented speeds, resulting in faster query response times and improved overall throughput.
Performance Evaluation
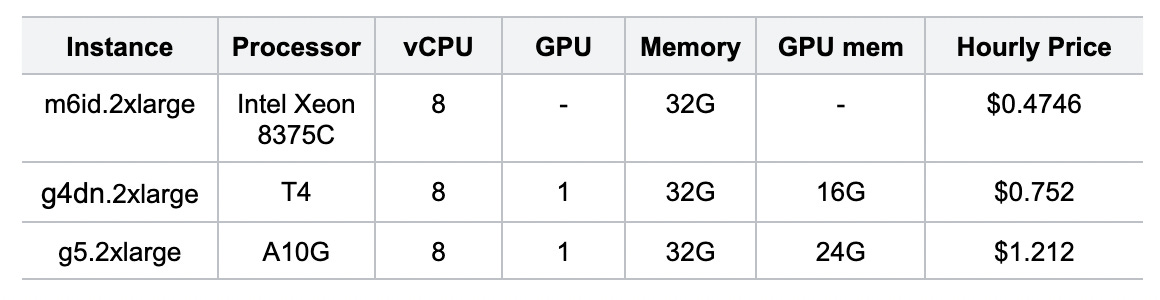
For this evaluation, we utilized three publicly available instance types on AWS:
-
m6id.2xlarge: This instance type is powered by the Intel Xeon 8375C CPU.
-
g4dn.2xlarge: This GPU-accelerated instance is equipped with an NVIDIA T4 GPU.
-
g5.2xlarge: This instance type features the NVIDIA A10G GPU.
By leveraging these diverse instance types, we aimed to evaluate the performance and efficiency of Milvus with CAGRA integration across different hardware configurations. The m6id.2xlarge instance served as a baseline for CPU-based performance, while the g4dn.2xlarge and g5.2xlarge instances allowed us to assess the benefits of GPU acceleration using the NVIDIA T4 and A10G GPUs, respectively.
We used two publicly available vector datasets from VectorDBBench:
-
OpenAI-500K-1536-dim: This dataset consists of 500,000 vectors, each with a dimensionality of 1,536. It is derived from the OpenAI language model.
-
Cohere-1M-768-dim: This dataset contains 1 million vectors, each with a dimensionality of 768. It is generated from the Cohere language model.
These datasets were specifically chosen to evaluate the performance and scalability of Milvus with CAGRA integration under different data volumes and vector dimensionalities. The OpenAI-500K-1536-dim dataset allows for assessing the system’s performance with a moderately large dataset of extremely high-dimensional vectors. In contrast, the Cohere-1M-768-dim dataset tests the system’s ability to handle larger volumes of moderately high-dimensional vectors.
Index Building Time
We compare the index-building time between Milvus with the CAGRA GPU acceleration framework and the standard Milvus implementation using the HNSW index on CPUs.
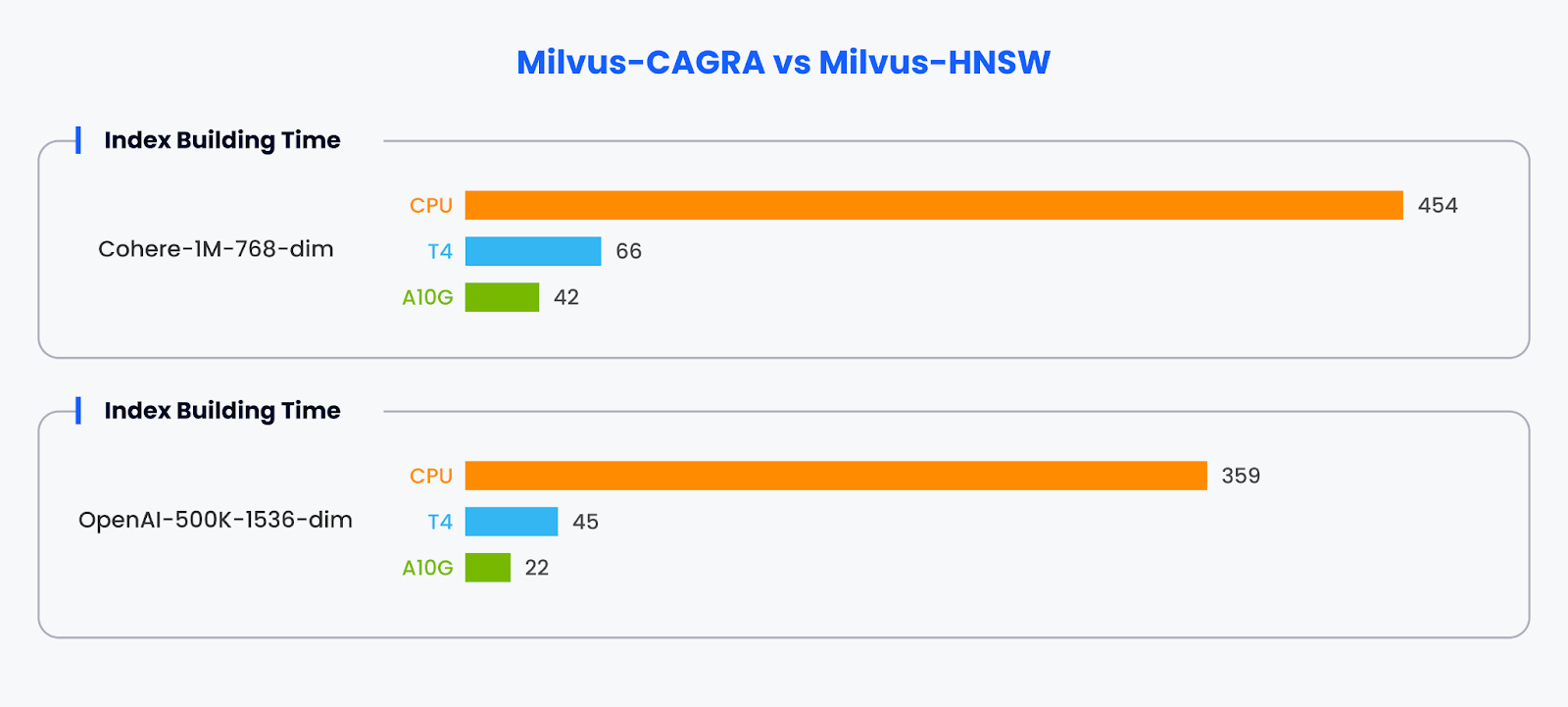
For the Cohere-1M-768-dim dataset, the index building times are:
-
CPU (HNSW): 454 seconds
-
T4 GPU (CAGRA): 66 seconds
-
A10G GPU (CAGRA): 42 seconds
For the OpenAI-500K-1536-dim dataset, the index building times are:
-
CPU (HNSW): 359 seconds
-
T4 GPU (CAGRA): 45 seconds
-
A10G GPU (CAGRA): 22 seconds
The results clearly show that CAGRA, the GPU-accelerated framework, significantly outperforms the CPU-based HNSW index building, with the A10G GPU being the fastest across both datasets. The GPU acceleration provided by CAGRA reduces the index building time by up to an order of magnitude compared to the CPU implementation, demonstrating the benefits of leveraging GPU parallelism for computationally intensive vector operations like index construction.
Throughput
We present a performance comparison between Milvus with the CAGRA GPU acceleration framework and the standard Milvus implementation using the HNSW index on CPUs. The metric being evaluated is Queries Per Second (QPS), which measures the throughput of query execution.
We varied the batch size during the evaluation process, representing the number of queries processed concurrently, from 1 to 100. This comprehensive range of batch sizes allowed us to conduct a realistic and thorough evaluation, assessing the performance under different query workload scenarios.
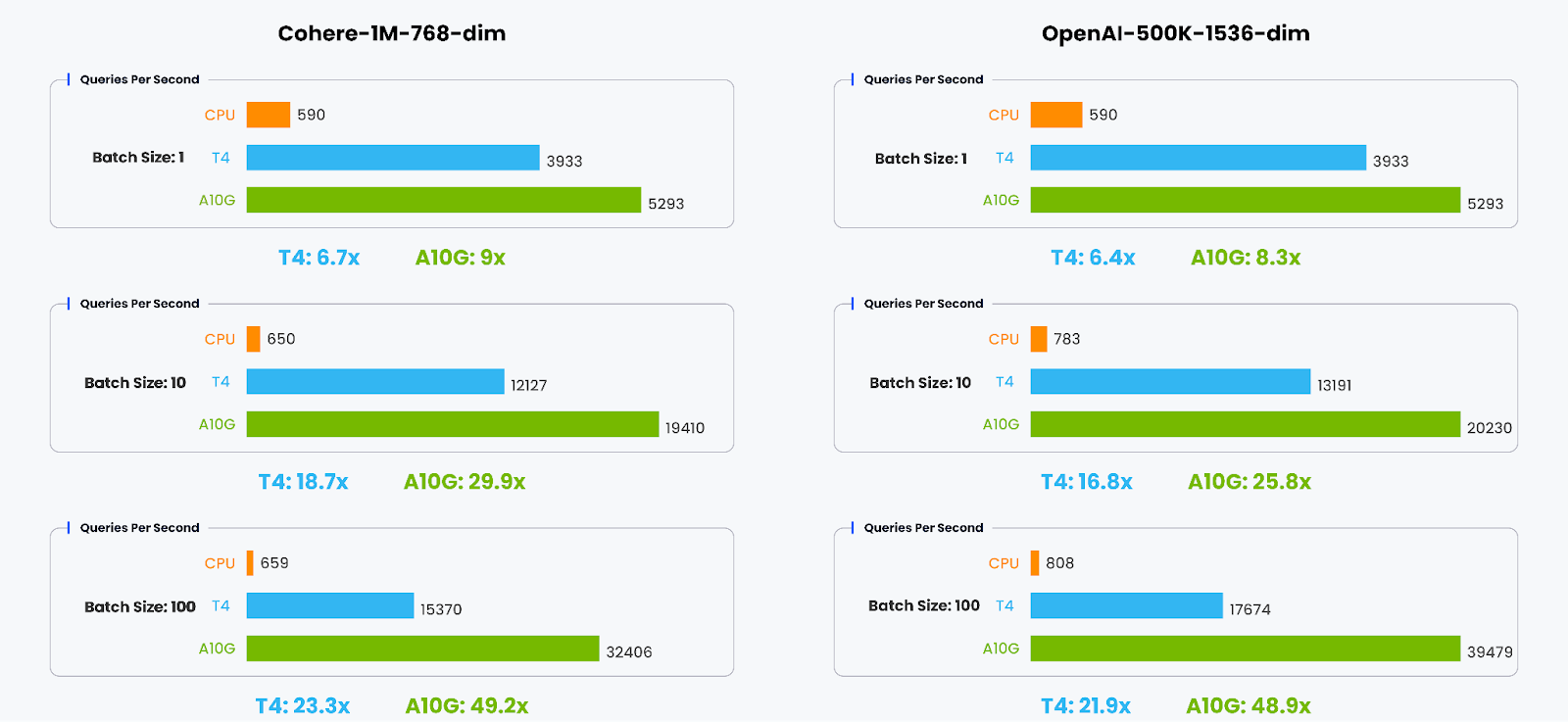
Looking at the charts, we can see that:
-
For a batch size of 1, the T4 is 6.4x to 6.7x faster than the CPU, and the A10G is 8.3x to 9x faster.
-
When the batch size increases to 10, the performance improvement is more significant: T4 is 16.8x to 18.7x faster, and A100 is 25.8x to 29.9x faster.
-
With a batch size of 100, the performance gain continues to grow: T4 is 21.9x to 23.3x faster, and A100 is 48.9x to 49.2x faster.
The results demonstrate the substantial performance gains achieved by leveraging GPU acceleration for vector database queries, particularly for larger batch sizes and higher-dimensional data. Milvus with CAGRA unlocks the parallel processing capabilities of GPUs, enabling significant throughput improvements and making it well-suited for demanding vector database workloads.
Blazing New Trails
The integration of NVIDIA’s CAGRA GPU acceleration framework into Milvus 2.4 represents a groundbreaking achievement in vector databases. By harnessing GPUS’ massively parallel computing power, Milvus has unlocked unprecedented levels of performance for vector indexing and search operations, ushering in a new era of real-time, high-throughput vector data processing.
The unveiling of Milvus 2.4, a collaboration between Zilliz and NVIDIA, exemplifies the power of open innovation and community-driven development by bringing GPU acceleration to vector databases. This milestone marks the beginning of a transformative era, where vector databases are poised to experience exponential performance leaps akin to NVIDIA’s remarkable achievement of increasing GPU computing power by 1000x over the past eight years. In the coming decade, we will witness a similar surge in vector database performance, catalyzing a paradigm shift in how we process and harness the immense potential of unstructured data.