
Generative AI has recently witnessed an exciting development: using language to understand images, video, audio, molecules, time-series, and other “modalities.” Multimodal retrieval exemplifies this advancement, allowing us to search one modality using another. Think of Google image search or Spotify song search. Before recent breakthroughs in deep learning and Gen AI, performing ML on such unstructured data posed significant challenges due to the lack of suitable feature representations. In this article, Stefan Webb, Developer Advocate at Zilliz, explores Multimodal Retrieval, its importance, implementation methods, and future prospects in multimodal Gen AI.
Why Multimodal Retrieval Matters
Multimodal Retrieval primarily enables us to search images, audio, and videos using text queries. However, it also serves a crucial role in grounding large language models (LLMs) in factual data and reducing hallucinations. In multimodal RAG (retrieval-augmented generation), we use the user’s query to retrieve multiple similar images and text strings, augmenting the prompt with this relevant information. This approach either provides the LLM with relevant facts or supplies query-answer pairs as demonstrations for in-context learning. Multimodal retrieval powers numerous applications, including multimedia search engines, visual question-answering systems, and more.
How Multimodal Retrieval Works
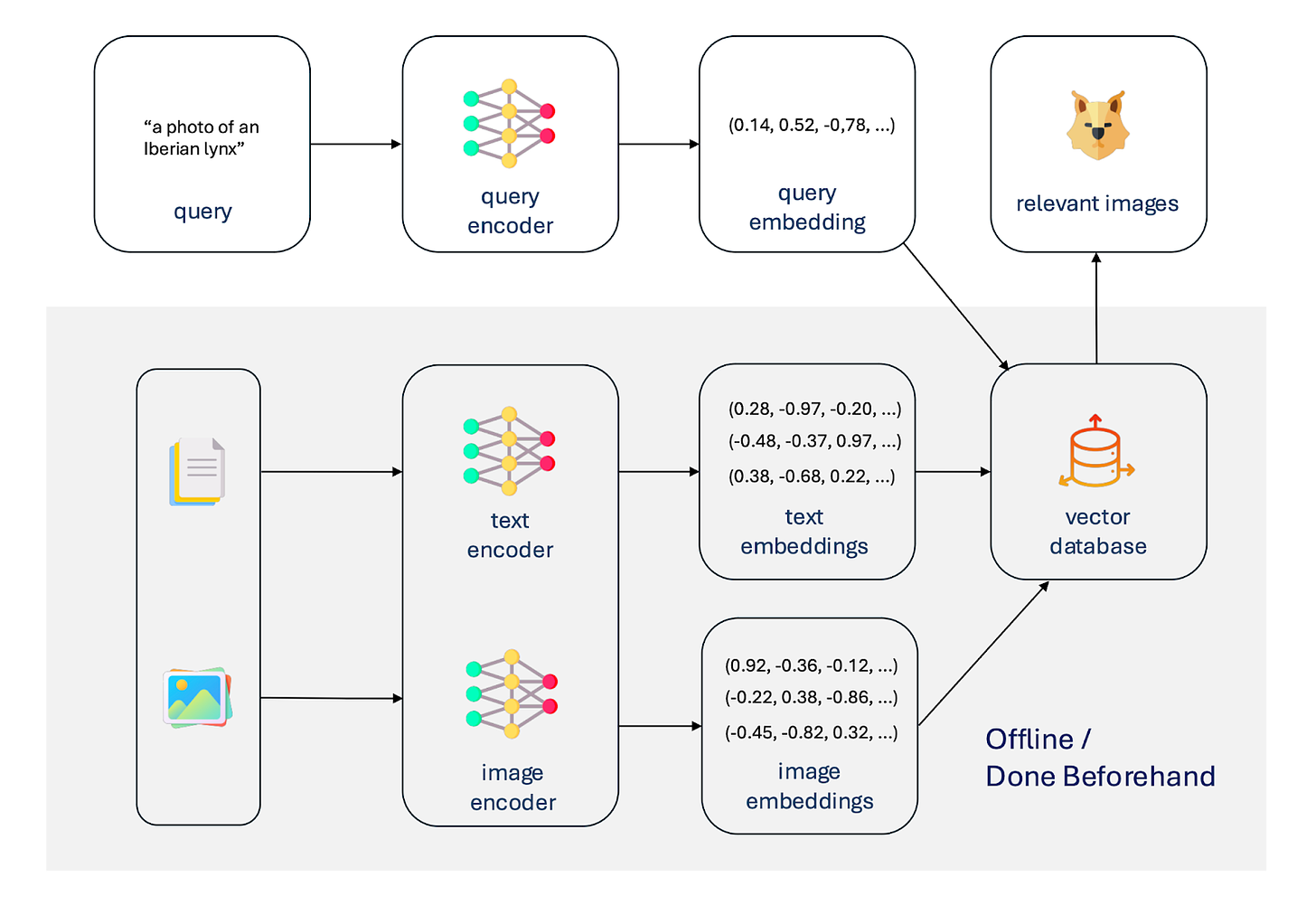
At a high level, Multimodal Retrieval follows these steps:
-
We populate a vector database with embeddings of the data of interest before accepting user queries.
-
We process the user’s query to return and generate an output response.
To compare text and image embeddings effectively, we can’t use embedding models trained separately. The embedding space differs between modalities and even for the same modality if we retrain the model. Therefore, we need to produce aligned encoders for each modality. This alignment ensures that semantically similar sentences and images have embeddings close to each other in either cosine or Euclidean distance.
Embedding models typically use the Transformer architecture for text, images, or other modalities. CLIP (Contrastive Language-Image Pretraining) stands out as a seminal method. A similar architecture to GPT-2 is used for the text encoder, and a Vision Transformer (ViT) is used as the image encoder. Both are trained together from scratch using a contrastive loss function, which minimizes the cosine distance between embeddings of matching (image, text) pairs while penalizing small distances for dissimilar pairs. At each gradient step of learning, a minibatch of around size 32k is used to construct similar and dissimilar (image, text) pairs.
After embedding our dataset’s text and images, we store these embeddings in a vector database. Vector databases differ from relational databases by offering efficient data structures and algorithms for searching vectors by distance. While a naive algorithm comparing the query vector to every vector in the database would have O(N) runtime, search algorithms like Hierarchical Navigable Small Worlds (HNSW) and Inverted File index (IVF) have, respectively, O(log(N)) and O(K + N/K) runtimes (on average), where K is the number of clusters used for grouping the vectors. This efficiency comes at the cost of, for example, an O(N*log(N)) index construction step for HNSW and extra memory usage but allows vector search speeds to scale to web scale. We can also reduce storage cost through techniques like Product Quantization (PQ). As a purpose-built high-performance vector database, Milvus is open source and offers features for running on single machines or clusters, scaling to tens of billions of vectors, and searching with millisecond latency.
Once we’ve constructed our multimodal dataset’s vector database, we perform Multimodal Retrieval by embedding the user’s query and searching the database for similar embeddings and their associated metadata. For instance, given a user query describing an image, we can retrieve similar images. The query embedding model is typically the same as the embedding model used for constructing the database, although it is possible to fine-tune it for better retrieval. More complex pipelines might involve filtering the query for appropriateness or relevance, rewriting it to facilitate search, searching both text and image embeddings, combining results, reranking retrieved results with a separate model, and filtering the output.
Key Requirements for Multimodal Retrieval
-
A large multimodal dataset or pretrained multimodal embedding models
-
A scalable vector database
-
Infrastructure to host the vector database, accept user queries (input), and return similar database entries (output)
Creating a large multimodal dataset from scratch requires ingenuity to scale up. For example, common image search datasets use (image, alt text) pairs scraped from the web. In the MagicLens model, triplets of (source image, instruction, target image) are formed by scraping similar images from the same webpage, and using an Large Language-Vision Model (LLVM) to synthesize natural language instructions for transforming the source into the target. It’s often more convenient to use pre-existing datasets or pretrained models – state-of-the-art examples with commercial-use licenses are available from Hugging Face.
Vector database implementations like Milvus address the second and third challenges by handling distributed system aspects and performing efficient searches at scale. Check out this demo implementing Multimodal RAG with Milvus for image search. For those who prefer not to manage their own vector database, hosted services like Zilliz Cloud are available.
Future Directions
Much exciting work has been happening at the intersection of multimodal retrieval and RAG since the idea was first examined in MuRAG (Google, 2022). As an example, see the following:
In this notebook, a graph database is combined with a vector database to search relationships over entities and concepts. A routing component is added to the RAG system that introspects the query to decide whether to retrieve the information from the vector database, the graph database, or defer to a web search.
Here are some further examples:
Multimodal Gen AI is not limited to just web-mined text and image data. Some recent work examines multimodal data in other domains:
-
non-speech audio; and,
For some recent interesting applications see:
-
agentic tool-usage; and,
Conclusion
Multimodal Retrieval opens up exciting possibilities for searching and understanding diverse data types using natural language. As we continue to refine these techniques and explore new applications, we can expect to see increasingly sophisticated and powerful AI systems that bridge the gap between human communication and machine understanding across multiple modalities.