In this post, Jordan Burgess, co-founder and Chief Product Officer at Humanloop, discusses the techniques for going from an initial demo to a robust production-ready application and explain how tools like Humanloop can help you get there. He covers best practices in prompt engineering, retrieval-augmented generation (RAG) and fine-tuning. Let’s dive in!
You need to optimize your LLMs to get from prototype to production
Creating an impressive AI demo that works part of the time can be easy, but to get to production, you’re always going to need to iterate and improve your LLM application’s performance. The three most common techniques for improving your application are prompt engineering, retrieval augmented generation (RAG) and fine-tuning.
-
Prompt Engineering: Tailoring the prompts to guide the model’s responses.
-
Retrieval-Augmented Generation (RAG): Enhancing the model’s context understanding through external data.
-
Fine-tuning: Modifying the base model to better suit specific tasks.
A common mistake is to think that this is a linear process and should be done in that order! But RAG and fine-tuning solve different problems and the usual path is more iterative, alternating between all three techniques depending on what’s the limiting factor to your application’s performance. Humanloop helps you to approach this process systematically.
You should iteratively ask yourself two questions:
-
Are the problems because the model does not have access to the right knowledge? — if yes, then context optimization (prompt engineering and RAG) are your best bets.
-
Is the problem accuracy or formatting? — if yes, then you likely want to consider fine-tuning.
But first, you need evals
“If you can’t measure it, you can’t improve it.” — Peter Drucker
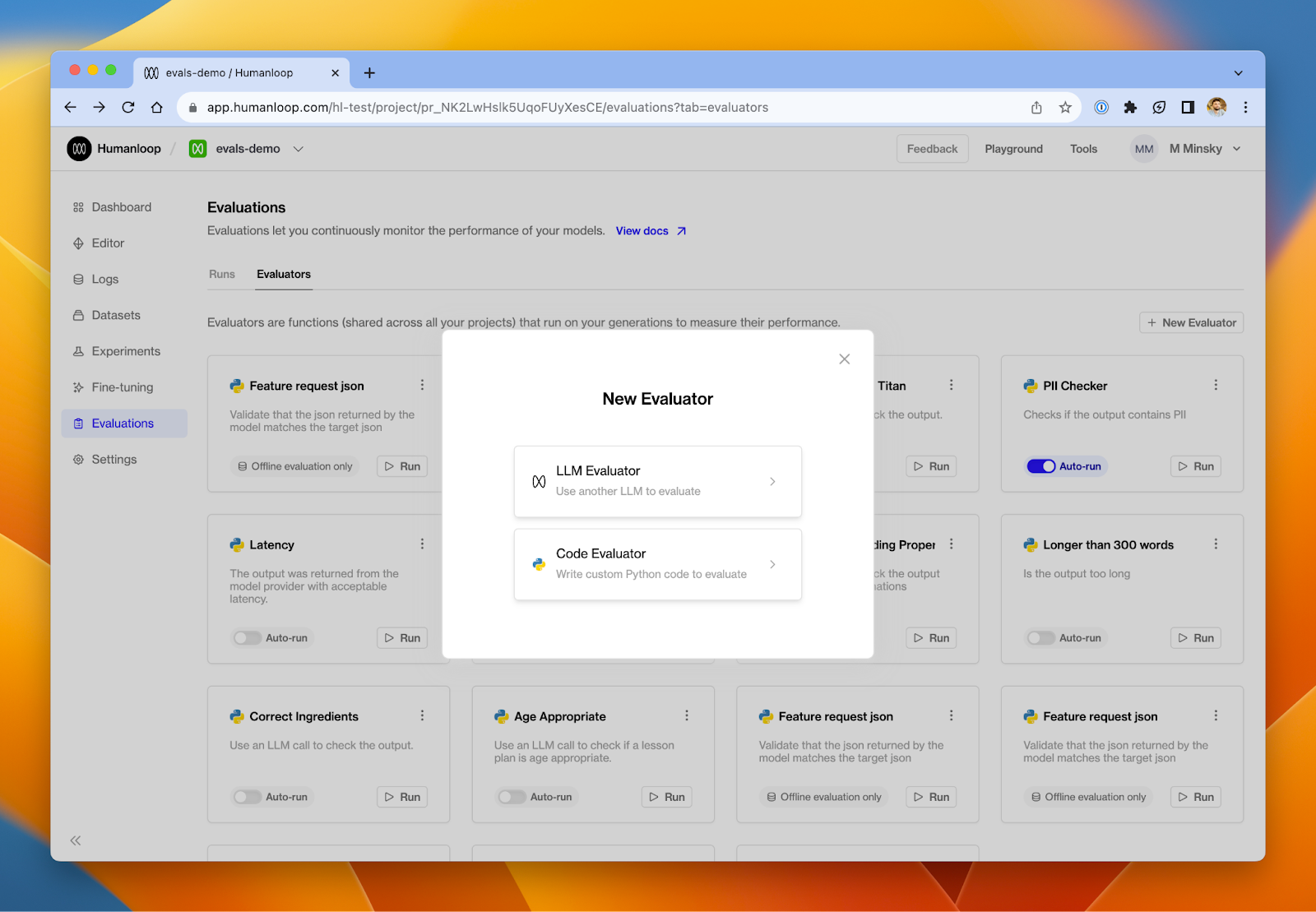
The most crucial step in the optimization process is setting up a solid evaluation framework. Without a clear understanding of your model’s performance, it’s impossible to tell if you’re making progress. The goal of evaluation is not just to identify where the model falls short, but also to uncover actionable insights that guide your optimization strategy. Whether you’re refining prompts, tweaking RAG, or fine-tuning the model, evals should help you know what to try next.
Here are some of the most common evaluation techniques:
-
Outsourced human annotation: AKA paying people to tell you whether something is good or bad. It’s often expensive, slow and challenging to ensure consistent quality.
-
Internal human review: Having your team internally review outputs ensures quality but can be slow and resource-intensive.
-
Model-based evaluation: Using another LLM to evaluate your system’s performance. This has become increasingly effective with powerful general models.
-
Code-based evaluation: Implementing custom heuristics defined in code to assess specific aspects of the model’s output.
-
Accuracy Metrics: If you have clear targets, metrics like F1, precision, recall, and BLEU can provide objective measures of your model’s accuracy.
-
End-user feedback and A/B testing: Often the feedback that matters most! This can include direct user responses as well as implicit actions indicating user preferences. However, it requires having an early version of your system available to users.
LLMOps platforms like Humanloop offer an integrated process for evaluating your prompts with the tools you need for prompt engineering and fine-tuning. For RAG specifically, information retrieval based scoring can be applicable. Open source eval frameworks like RAGAS can help evaluate retrieval-based scoring.
Do prompt engineering first (and last!)
Prompt engineering should nearly always be the first thing you explore in optimizing your LLM performance. In fact, it should be one of the things you also re-explore after RAG, fine-tuning, or other advanced techniques, given how core the prompt is to LLM generations. For more guidance, we recommend starting with Prompt Engineering 101 and the very through Prompt Engineering Guide.
Even with prompt engineering alone, you can make sufficient inroads on the two axes of optimization. If the issue is with the output, you can constrain the response to be JSON, or to follow a specific format with tool calling. You can also add in examples of the task being performed (‘few-shot learning’) which can help the model understand the task better.
If the issue is with context, you can prompt-stuff (technical term) with all the relevant and maybe-relevant context it needs. The main limitation is the size of the context window and what you’re willing to pay in cost and latency.
Evaluate and version your prompts to make sure you’re making progress
When prompt engineering, keeping track of changes to your prompts and parameters is key. Every adjustment should be recorded and evaluated systematically, helping you understand which changes improve performance and which don’t.
At this stage it’s helpful to have a specialized prompt development tool like Humanloop. A prompt editor that is paired with an evaluation framework can systematize iteration and allow engineers to more easily collaborate with domain experts.
After prompt engineering, you should identify where the largest gaps are. From this, you can decide whether to explore RAG or fine-tuning.
Fine-tune to optimize performance, improve efficiency and become defensible
Fine-tuning is continuing the training process of the LLM on a smaller, domain-specific dataset. This can significantly improve the model’s performance on specialized tasks by adjusting the model’s parameters themselves, rather than just changing the prompt.
Think of fine-tuning like compiling code. It’s an optimization step for something that’s mostly already working
One of the biggest challenges with fine-tuning is having the right dataset and curating it. This is an area where having the right infrastructure can be very helpful. A very common workflow is to use your evaluation data to filter your production logs to find the best performing examples and then fine-tune on that data. This process can often be repeated multiple times with continued improvement. Tools like Humanloop help here because they allow you to log user data from your production applications alongside evaluation.
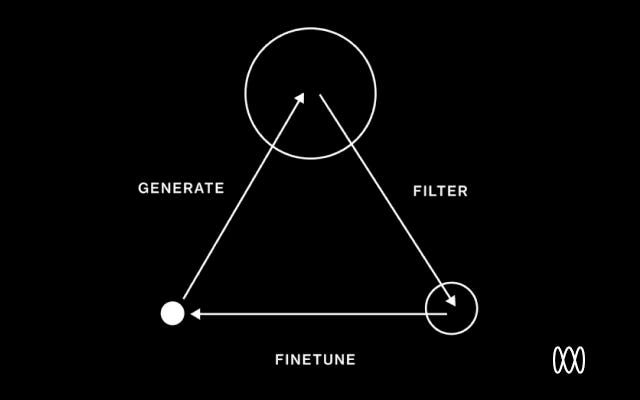
Why fine-tune?
There are two main benefits to fine-tuning:
Improving model performance on a specific task
Fine-tuning means you can pack in more examples. You can fine-tune on millions of tokens, whereas few-shot learning prompts are limited to 10s of thousands of tokens, depending on the context size. A fine-tuned model may lose some of its generality, but for its specific task, you should expect better performance.
Improving model efficiency
Efficiency for LLM applications means lower latency and reduced costs. This benefit is achieved in two ways. By specializing the model, you can use a much smaller model. Additionally, as you train only on input-output pairs, not the full prompt with any of its prompt engineering tricks and tips, you can discard the examples or instructions. This can further improve latency and cost.
Best practices for fine-tuning
For fine-tuning to work best you should start with a clear goal and a relevant, high-quality dataset. It’s crucial to fine-tune with data that exemplifies the type of output you need. Moreover, iterative testing is vital – start with small, incremental changes and evaluate the results before proceeding further. It matters a lot what you fine-tune on!
Use Retrieval-Augmented Generation (RAG) if the issues are due to context
When you’re dealing with LLMs, sometimes the challenge isn’t just about how the model generates responses, but about what context it has access to. The models have been trained on mostly public domain content from the web; not your company’s private data, nor the latest information from your industry.
This is where Retrieval-Augmented Generation (RAG) comes into play. It’s combining the capabilities of LLMs with the context of external data sources.
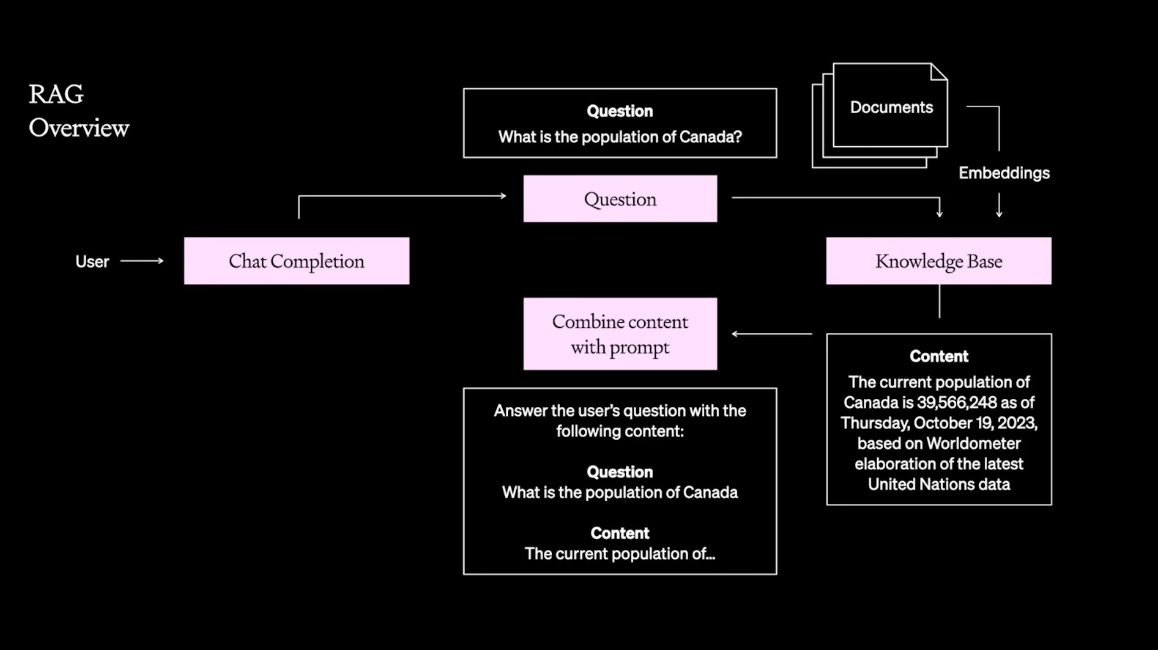
Setting up RAG
The first thing to do is to demonstrate performance with some handpicked few-shot examples. After which you may wish to operationalize this with a system for picking out those examples.
RAG can be as simple as creating a prompt template and inserting dynamic content fetched from a database. As LLM applications often work with natural language, it’s very common to use semantic search on a vector database, such as Qdrant, Chroma and Pinecone. Tool calling is a way to use the LLM to create the structured output necessary to directly call systems like traditional SQL databases. And Prompt Tools enable you to conveniently hook up resources into your prompts with having to build any data pipelines.
However, RAG is rarely a plug-and-play solution. Implementing RAG requires careful consideration of the sources you allow the model to access, as well as how you integrate this data into your LLM requests. It’s about striking the right balance between providing enough context to enhance the model’s responses while ensuring that the information it retrieves is reliable and relevant.
Combine all the techniques for optimal results
Remember, nearly all these techniques are additive.
Fine-tuning refines the model’s understanding of a task, making it adept at delivering the right kind of output. By pairing it with RAG, the model not only knows what to say but also has the appropriate information to draw from.
This dual approach leverages the strengths of both fine-tuning (for task-specific performance) and RAG (for dynamic, context-rich information retrieval), leading to a more performant LLM application.
Prompt engineering is always the first step in the optimization process. By starting with well-crafted prompts, you understand what’s the inherent capability of the model for your task – and prompt engineering may be all that you need!
Conclusion
For those building applications that rely on LLMs, the techniques shown here are crucial for getting the most out of this transformational technology. Understanding and effectively applying prompt engineering, RAG, and fine-tuning are key to transitioning from a promising prototype to a robust production-ready model.
The two axes of optimization – what the model needs to know and how the model needs to act – provide a roadmap for your efforts. A solid evaluation framework and a robust LLMOps workflow are the compasses that guide you, helping you to measure, refine, and iterate on your models.
I encourage readers to delve deeper into these methods and experiment with them in their LLM applications for optimal results. If you’re interested in whether an integrated platform like Humanloop can provide the LLMOps infrastructure you need to track, tune, and continually improve your models, please request a demo.