In this guest post, Jael Gu, an algorithm engineer at Zilliz, will delve into the constraints of OpenAI’s built-in retrieval and walk you through creating a customized retriever using Milvus, an open-source vector database.
OpenAI once again made headlines with a slew of releases during its DevDay, unveiling the GPT-4 Turbo model, the new Assistants API, and a range of enhancements. The Assistants API emerges as a powerful tool helping developers craft bespoke AI applications catering to specific needs. It also allows them to tap into additional knowledge, longer prompt length, and tools for various tasks.
While OpenAI Assistants come with an integrated retrieval feature, it’s not perfect — think restrictions on data scale and lack of capability in customization. This is precisely where a custom retriever steps in to help. By harnessing OpenAI’s function calling capabilities, developers can seamlessly integrate a customized retriever, elevating the scale of the additional knowledge and better fitting diverse use cases. Let’s dive in!
Limitations of OpenAI’s retrieval in Assistants and the role of custom retrieval solutions
OpenAI’s built-in Retrieval feature represents a leap beyond the model’s inherent knowledge, enabling users to augment it with extra data such as proprietary product information or user-provided documents. However, it grapples with notable limitations.
Scalability constraint
OpenAI Retrieval imposes file and total storage constraints that might fall short for extensive document repositories:
-
A maximum of 20 files per assistant
-
A cap of 512MB per file
-
A hidden limitation of 2 million tokens per file, uncovered during our testing
-
A total size limit of less than 100GB per organization
For organizations with extensive data repositories, these limitations pose challenges. A scalable solution that grows seamlessly without hitting storage ceilings becomes imperative. Integrating a custom retriever powered by a vector database like Milvus or Zilliz Cloud (the managed Milvus) offers a workaround for the file limitations inherent in OpenAI’s built-in Retrieval.
Lack of customization
While OpenAI’s Retrieval offers a convenient out-of-the-box solution, it cannot consistently align with every application’s specific needs, especially regarding latency and search algorithm customization. Utilizing a third-party vector database grants developers the flexibility to optimize and configure the retrieval process, catering to production needs and enhancing overall efficiency.
Lack of multi-tenancy
Retrieval is a built-in feature in OpenAI Assistants that only supports individual user usage. However, if you are a developer aiming to serve millions of users with both shared documents and users’ private information, the built-in retrieval feature cannot help. Replicating shared documents to each user’s Assistant escalates storage costs, while having all users share the same Assistant poses challenges in supporting user-specific private documents.
The following graph shows that storing documents in OpenAI Assistants is expensive ($6 per GB per month; for reference, AWS S3 charges $0.023), making storing duplicate documents on OpenAI incredibly wasteful.
For organizations harboring extensive datasets, a scalable, efficient, and cost-effective retriever that aligns with specific operational demands is imperative. Fortunately, with OpenAI’s flexible function calling capability, developers can seamlessly integrate a custom retriever with OpenAI Assistants. This solution ensures businesses can harness the best AI capabilities powered by OpenAI while maintaining scalability and flexibility for their unique needs.
Leveraging Milvus for customized OpenAI retrieval
Milvus is an open-source vector database that can store and retrieve billions of vectors within milliseconds. It is also highly scalable to meet users’ rapidly growing business needs. With rapid scaling and ultra-low latency, the Milvus vector database is among the top choices for building a highly scalable and more efficient retriever for your OpenAI assistant.
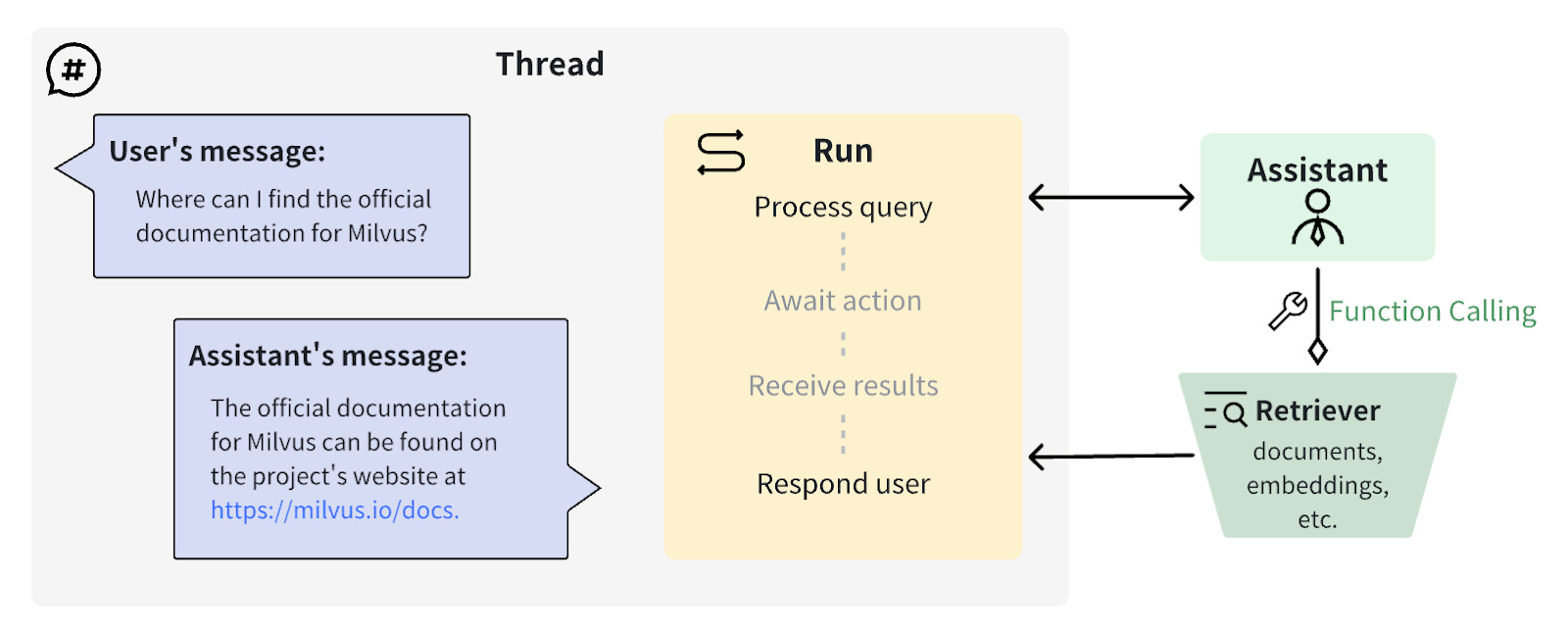
Building a custom retriever with OpenAI function calling and Milvus vector database
Let’s start building the custom retriever and integrate it with OpenAI by following the step-by-step guide.
-
Set up the environment.
pip install openai==1.2.0
pip install langchain==0.0.333
pip install pymilvus
export OPENAI_API_KEY=xxxx # Enter your OpenAI API key here
-
Build a custom retriever with a vector database. This guide uses Milvus as the vector database and LangChain as the wrapper.
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
# Prepare retriever
vector_db = Milvus(
embedding_function=OpenAIEmbeddings(),
connection_args = {'host': 'localhost', 'port': '19530'}
)
retriever = vector_db.as_retriever(search_kwargs={'k': 5}) # change top_k here
-
Ingest extra documents into Milvus. Documents will be parsed, divided into chunks, and then transformed into embeddings before being ingested into the vector database. Developers can customize each step to improve the retrieval quality.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Parsing and chunking the document.
filepath = ‘path/to/your/file’
doc_data = TextLoader(filepath).load_and_split(
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
)
# Embedding and insert chunks into the vector database.
vector_db.add_texts([doc.page_content for doc in doc_data])
Now, you’ve successfully built a custom retriever capable of operating semantic search based on your private or proprietary data. Next, you must integrate this retriever with OpenAI Assistants to enable content generation.
-
Create an Assistant with OpenAI’s Function Calling feature. The Assistant is instructed to use a function tool called `CustomRetriever` when responding to queries.
import os
from openai import OpenAI
# Setup OpenAI client.
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# Create an Assistant.
my_assistant = client.beta.assistants.create(
name='Chat with a custom retriever',
instructions='You will search for relevant information via retriever and answer questions based on retrieved information.',
tools=[
{
'type': 'function',
'function': {
'name': 'CustomRetriever',
'description': 'Retrieve relevant information from provided documents.',
'parameters': {
'type': 'object',
'properties': {'query': {'type': 'string', 'description': 'The user query'}},
'required': ['query']
},
}
}
],
model='gpt-4-1106-preview', # Switch OpenAI model here
)
-
The Assistant performs query-answering tasks asynchronously. `Run` is an invocation of an Assistant during a Thread. During the run operation, the Assistant decides whether a function needs to call `CustomRetriever` and waits for the function call result.
QUERY = 'ENTER YOUR QUESTION HERE'
# Create a thread.
my_thread = client.beta.threads.create(
messages=[
{
'role': 'user',
'content': QUERY,
}
]
)
# Invoke a run of my_assistant on my_thread.
my_run = client.beta.threads.runs.create(
thread_id=my_thread.id,
assistant_id=my_assistant.id
)
# Wait until my_thread halts.
while True:
my_run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=my_run.id)
if my_run.status != 'queued':
break
-
Now, the Assistant is waiting for the function call result. Make a vector search for the query and submit the result.
# Conduct vector search and parse results when OpenAI Run ready for the next action
if my_run.status == 'requires_action':
tool_outputs = []
for tool_call in my_run.required_action.submit_tool_outputs.tool_calls:
if tool_call.function.name == 'Custom Retriever':
search_res = retriever.get_relevant_documents(QUERY)
tool_outputs.append({
'tool_call_id': tool_call.id,
'output': ('nn').join([res.page_content for res in search_res])
})
# Send retrieval results to your Run service
client.beta.threads.runs.submit_tool_outputs(
thread_id=my_thread.id,
run_id=my_run.id,
tool_outputs=tool_outputs
)
-
Extract and parse out the complete conversation with OpenAI.
messages = client.beta.threads.messages.list(
thread_id=my_thread.id
)
for m in messages:
print(f'{m.role}: {m.content[0].text.value}n')
There you go! You’ve successfully chatted with your OpenAI Assistant about the provided knowledge by leveraging a custom retriever powered by Milvus.

Conclusion
While OpenAI Assistants’ built-in retrieval tool is impressive, it grapples with limitations such as storage constraints, scalability issues, and a lack of customization for diverse user needs. It caters only to individual users, posing challenges for applications with millions of users and both shared and private documents.
Crafting a custom retriever using a robust vector database like Milvus or Zilliz Cloud (the fully managed version of Milvus) proves helpful in overcoming the above challenges. This approach offers increased flexibility and file management control through the OpenAI Assistant API integration.