
In this guest post, Fendy Feng from ZIlliz explores how RAG works, RAG challenges, and advanced RAG techniques like Small to Slide RAG and ColPali. A must read!
Large language models (LLMs) have demonstrated exceptional capabilities in understanding and generating various types of content, text or visual, making them widely adopted across various industries. Despite their versatility, LLMs often produce inaccurate or fabricated information—known as hallucinations—due to limited domain knowledge and outdated data.
Retrieval augmented generation (RAG) is a technique that addresses these challenges by combining LLMs’ generative abilities with retrieval systems that fetch relevant information from external sources. By grounding LLM responses in real-world, up-to-date data, RAG improves the accuracy and contextual relevance of answers and enhances the system’s overall efficiency.
Small to Slide is a new approach that enhances the performance of multimodal LLMs when dealing with visual data like presentations or documents with images. We’ll explore how RAG works, RAG challenges, and advanced RAG techniques like Small to Slide RAG.
RAG Challenges and Advanced RAG Techniques
While RAG offers powerful capabilities, it also faces challenges that can impact its effectiveness, especially as data becomes large and complex.
-
Speed: Searching larger databases takes longer. This can be mitigated by leveraging hardware-accelerated computing, such as optimizing for GPUs or other high-performance systems.
-
Accuracy: Ensuring that we’re retrieving the most relevant information is challenging. Developers need ways to balance performance and data accuracy based on their needs.
-
Multimodal Data: A basic RAG struggles with non-text data like images or charts. Handling different types of vector data becomes crucial in these cases.
In the following sections, we’ll explore several advanced RAG techniques—Small to Big RAG, Small to Slide RAG, and ColPali—that address these challenges, enhancing RAG systems’ speed, accuracy, and versatility.
Small to Big RAG
Small to Big RAG is a method to enhance the accuracy of RAG systems. The core idea is to split documents into smaller, intent-focused chunks for precise searches but retrieve larger context sections rather than returning just the exact matching pieces to ensure LLMs can generate meaningful and complete responses. This is because while smaller chunks improve search precision by honing in on specific details, they can also miss critical context, leading to incomplete or inaccurate answers.
Let’s take a look at one example.
Consider the query: “Where does Ms. Churilo work?”
When processed, the embedding model might prioritize the less common word “Churilo” over more important terms like “work.” As a result, the system could retrieve sentences mentioning “Churilo” but fail to provide the key information: “Chris is currently VP of Marketing at Zilliz.”
Small to Big RAG addresses this limitation by retrieving the entire paragraph where her role is mentioned, giving the LLM the full context needed to deliver a correct and complete response.
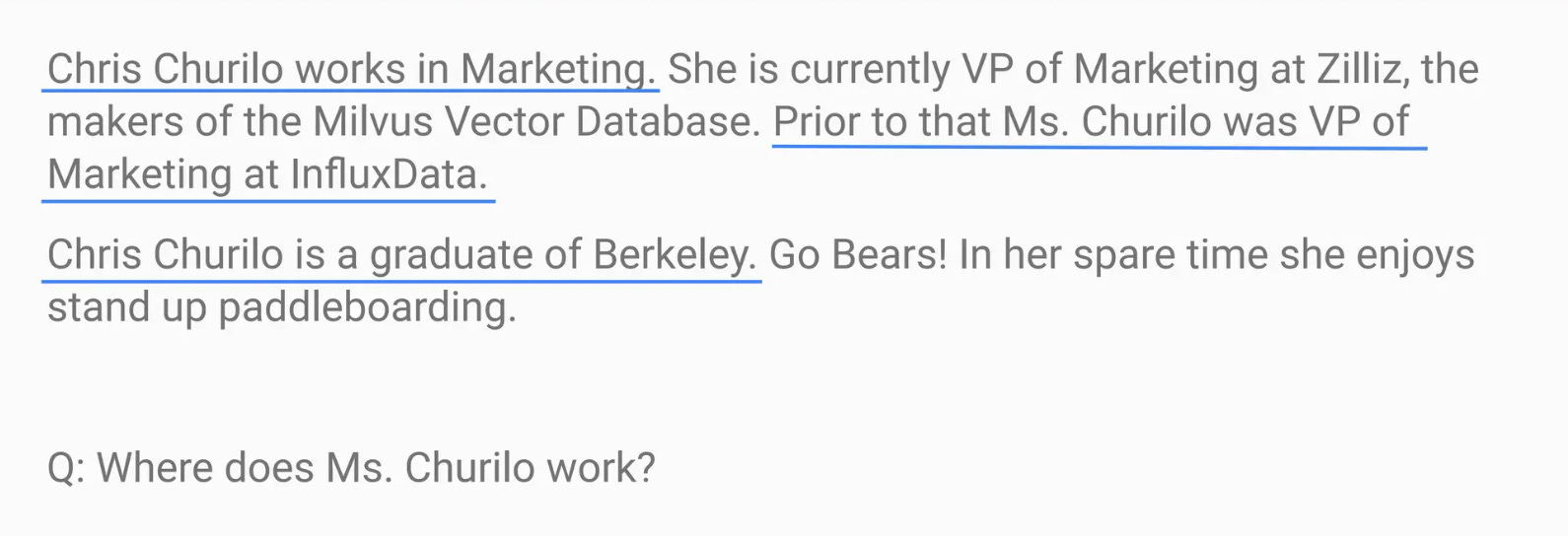
Figure: Incorrect retrieval in traditional RAG
Small to Big RAG is particularly effective for handling complex or multi-layered text data. In a technical support system, for example, retrieving a single sentence with a relevant keyword might leave out surrounding details that are critical for understanding. Instead, Small to Big RAG retrieves all sections related to the query. For instance, when a user asks, “How do I reset my password?” the system could retrieve the paragraph with the direct answer and include additional context, such as security recommendations, making the response more comprehensive and useful.
By combining the precision of smaller embeddings with the contextual depth of broader retrieval, Small to Big RAG ensures a balance between accuracy and completeness. This approach enables AI systems to provide answers that are not only precise but also rich in context, improving their reliability in real-world applications.
Small to Slide RAG
While Small to Big RAG excels at handling text-based data, it struggles to capture information embedded in visuals such as slides, charts, or graphs. Small to Slide RAG is an improved RAG method that solves this problem by embedding text from visual elements like slides but retrieving the entire slide image. This retrieved result is then provided to and processed by a multimodal LLM capable of analyzing both text and images.
Here’s how it works:
-
Text Embedding: The system extracts and embeds text from slides.
-
Visual Retrieval: Instead of retrieving only text, it retrieves the entire slide image containing the relevant information.
-
Multimodal Processing: The retrieved slide images are fed into a multimodal LLM (e.g., GPT-4 with vision capabilities) that can process both the visual and textual components simultaneously.
This method is particularly useful for handling complex documents where crucial information is conveyed through visuals. For example, in quarterly financial reports, key insights are often found in graphs or charts that traditional text-based RAG systems might miss. By retrieving and analyzing the entire slide image, Small to Slide RAG ensures no critical detail is overlooked, providing a more accurate and comprehensive response.
To demonstrate the power of Small to Slide RAG, this demo is a practical example using an Nvidia slide deck.
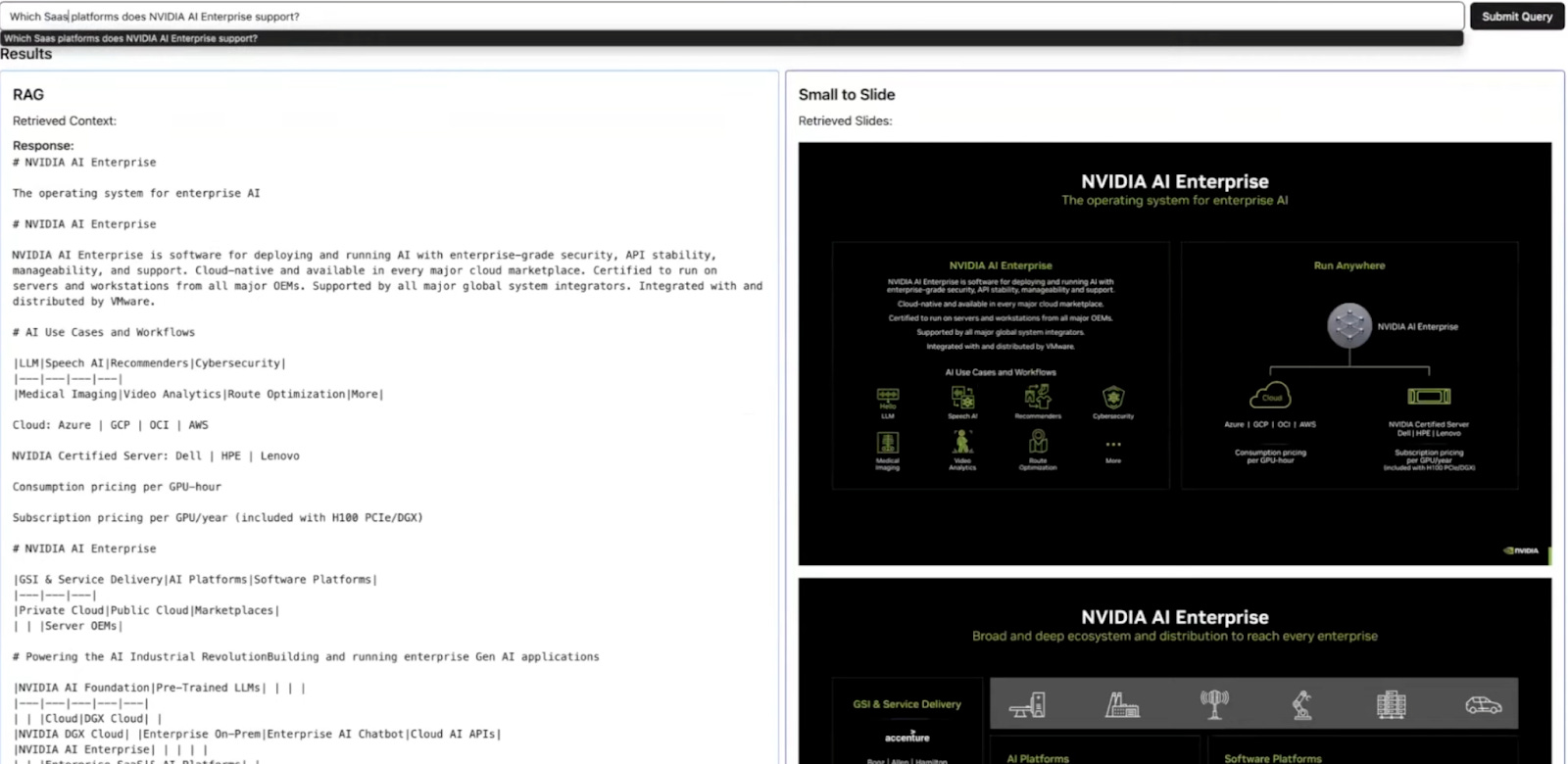
Figure: A comparison between the context retrieved by a traditional RAG and a Small to Slide RAG
In this demo, the context retrieved by a traditional RAG system is compared with Small to Slide RAG when answering the same question: “Which SaaS platforms does NVIDIA AI Enterprise support?“
-
Traditional RAG: The traditional text-based RAG system struggled to provide a complete answer. It relied solely on text extracted from the slides, missing critical information embedded in charts and diagrams. This limitation resulted in an incomplete and less informative response.
-
Small to Slide RAG: In contrast, Small to Slide RAG delivered far better results. The system retrieved the actual slide images containing the relevant information and fed them into a multimodal LLM (e.g., GPT-4 with vision capabilities). This allowed the model to interpret both the text and visual elements, generating a much more comprehensive and accurate answer.
This example illustrates the unique strength of Small to Slide RAG: its ability to handle complex documents where key information is spread across text and visuals, making it an invaluable tool for processing visually rich content.
For these RAG methods to function smoothly, they require infrastructure to manage complex queries and retrieval operations.
ColPali: Pushing the Boundaries
ColPali is a novel document retrieval model that pushes the boundaries of Retrieval-Augmented Generation (RAG). Unlike traditional methods that convert documents with visual data (like slides and PDFs) into text, ColPali works directly with the visual features of documents, enabling it to index and retrieve information without the error-prone step of text extraction.
How ColPali Works
While still in its early stages, ColPali changes the way we usually conduct document retrieval by focusing on visual data:
-
Documents are treated as images, bypassing text conversion entirely.
-
Multiple embeddings, similar to visual n-grams, are generated per image to capture fine-grained visual features.
-
Searches are conducted by comparing visual embeddings to the query, identifying the most relevant areas of the document.
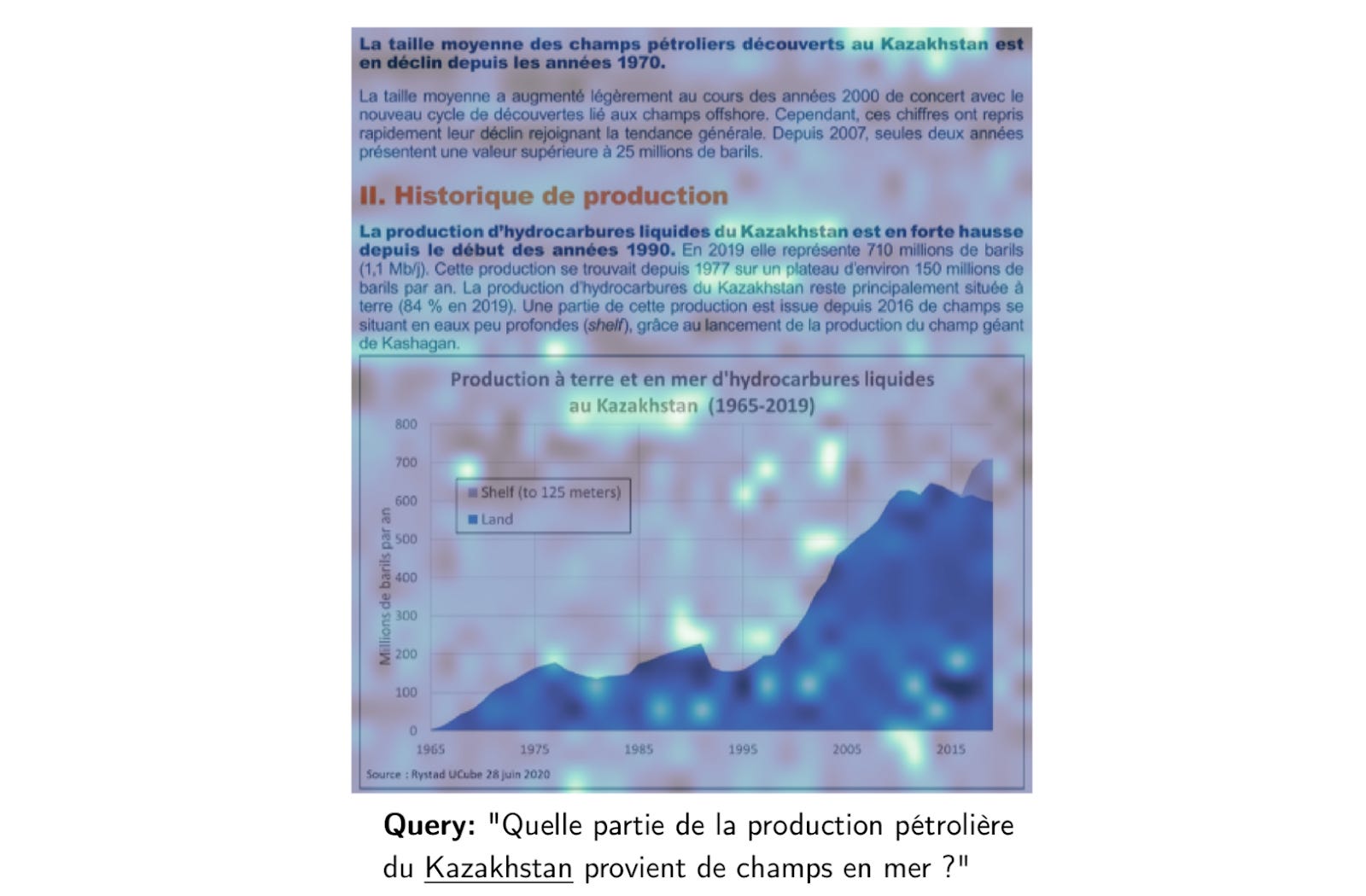
Figure: French document about oil production in Kazakhstan, with certain areas highlighted
Let’s look at the example shown in the image above: a French document about oil production in Kazakhstan. When asked about offshore oil production, ColPali highlights specific areas of the document—such as charts and diagrams—that are most relevant to the query. This ensures that both textual and visual elements are taken into account, offering a comprehensive understanding of the content.
Why ColPali is Exciting
ColPali offers several key advantages over traditional RAG systems:
-
By working directly with images, it avoids inaccuracies introduced by converting complex documents (e.g., PDFs) to text.
-
It captures visual information, such as layouts, diagrams, and formatting, that is often lost in text-based methods.
-
ColPali enables retrieval and search for visual data, opening possibilities in fields like technical design, legal documentation, and more.
A practical application of ColPali could be in architectural design reviews. Imagine an AI system analyzing blueprints and technical drawings directly. When queried about specific design elements, the system could highlight relevant parts of the drawings, incorporating both textual annotations and visual features.
ColPali Challenges and Limitations
While ColPali is promising, it is still in its early stages and comes with some challenges:
-
High Computational Demand: Generating and comparing multiple embeddings per image is computationally intensive, making GPU acceleration essential for practical use.
-
Limited Ecosystem: Compared to more established RAG techniques, there are fewer tools and resources available for implementing ColPali.
-
Language and Training-Specific Models: ColPali models currently rely on specific training datasets, which may limit generalization across different domains.
Pros and Cons of Each RAG Technique
Each of the techniques we have discussed above offers distinct advantages and limitations.
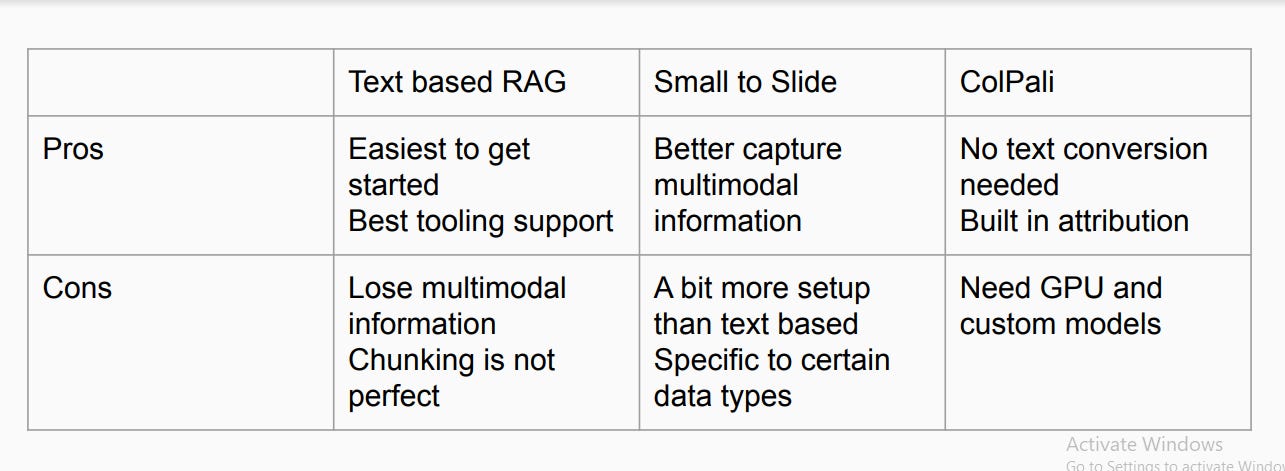
Figure: Comparison of different RAG techniques
Text-based RAG is the simplest to implement, benefiting from extensive tooling support. However, it struggles with maintaining multimodal information and doesn’t always handle chunking perfectly. On the other hand, Small to Slide improves the capture of multimodal data, though it demands a more intricate setup and works best with specific data types. Lastly, ColPali simplifies the process by avoiding the need for text conversion and integrating built-in attribution, but it requires GPUs and custom models, which may limit accessibility for some projects.
Implementing Advanced RAG: Practical Considerations
If you’re considering implementing these advanced RAG techniques in your own projects, here are some points to keep in mind.
Data Assessment
Look at the types of data you’re working with. If you have many documents with charts, images, or complex layouts, approaches like Small to Slide RAG might be particularly beneficial. For example, if you’re building a system to analyze financial reports, which often contain a mix of text, tables, and charts, Small to Slide RAG could provide more comprehensive insights than a text-only approach.
Computational Resources
Methods like Small to Slide RAG and ColPali can be more computationally intensive than traditional RAG. Ensure you have the necessary resources, particularly when working with large datasets.
Model Selection
These advanced techniques often require specific types of models. For Small to Slide RAG, you’ll need a multimodal LLM capable of processing text and images. Make sure you choose a model that fits your needs and that you have the resources to run it.
Vector Database Capabilities
Choosing the right vector database is crucial for implementing a RAG system tailored to your needs. For example, if you’re implementing a Small to Big RAG, you’ll need a vector database capable of efficiently retrieving larger chunks of text using embeddings generated from smaller chunks. Scalability becomes key if your application deals with massive amounts of vector data, such as billion-scale datasets. Solutions like Milvus and its managed service, Zilliz Cloud, are designed for these scenarios, offering highly scalable and efficient vector retrieval.
Evaluation Metrics
Develop clear metrics to evaluate the performance of your RAG system, including the relevance of retrieved information, the accuracy of generated responses, and the speed of retrieval and generation.
Iterative Development
RAG is evolving rapidly. Plan for an iterative development process that allows you to easily test and compare different approaches. Start with a basic RAG implementation, then gradually introduce more advanced techniques like Small to Big RAG or Small to Slide RAG. Continuously evaluate performance and user feedback to guide your development process.
Conclusion
RAG techniques continue to evolve, offering different approaches like text-based RAG, Small to Slide RAG, and ColPali to address varying needs. While text-based RAG provides a solid starting point for general applications, more specialized cases, especially those handling visual data, can benefit from advanced methods like Small to Slide RAG or ColPali.
Choosing the right method depends on your data and the resources at hand. Each approach provides a way to improve the efficiency and accuracy of AI systems, enabling a better balance between complexity, speed, and cost. By aligning your approach with your specific requirements, you can leverage RAG to build systems that offer users the right information at the right time in the right format.