In 1928, London was in the middle of a terrible health crisis, devastated by bacterial diseases like pneumonia, tuberculosis, and meningitis. Confined in sterile laboratories, scientists and doctors were stuck in a relentless cycle of trial and error, using traditional medical approaches to solve complex problems.
This is when, in September 1928, an accidental event changed the course of the world. A Scottish doctor named Alexander Fleming forgot to close a petri dish (the transparent circular box you used in science class), which got contaminated by mold. This is when Fleming noticed something peculiar: all bacteria close to the moisture were dead, while the others survived.
“What was that moisture made of?” wondered M. Flemming. This was when he discovered that Penicillin, the main component of the mold, was a powerful bacterial killer. This led to the groundbreaking discovery of penicillin, leading to the antibiotics we use today. In a world where doctors were relying on existing well-studied approaches, Penicillin was the unexpected answer.
Self-driving cars may be following a similar event. Back in the 2010s, most of them were built using what we call a « modular » approach. The software « autonomous » part is split into several modules, such as Perception (the task of seeing the world), or Localization (the task of accurately localize yourself in the world), or Planning (the task of creating a trajectory for the car to follow, and implementing the « brain » of the car). Finally, all these go to the last module: Control, that generates commands such as « steer 20° right », etc… So this was the well-known approach.
But a decade later, companies started to take another discipline very seriously: End-To-End learning. The core idea is to replace every module with a single neural network predicting steering and acceleration, but as you can imagine, this introduces a black box problem.

These approaches are known, but don’t solve the self-driving problem yet. So, we could be wondering: “What if LLMs (Large Language Models), currently revolutionizing the world, were the unexpected answer to autonomous driving?”
This is what we’re going to see in this article, beginning with a simple explanation of what LLMs are and then diving into how they could benefit autonomous driving.
Preamble: LLMs-what?
Before you read this article, you must know something: I’m not an LLM pro, at all. This means, I know too well the struggle to learn it. I understand what it’s like to google “learn LLM”; then see 3 sponsored posts asking you to download e-books (in which nothing concrete appears)… then see 20 ultimate roadmaps and GitHub repos, where step 1/54 is to view a 2-hour long video (and no one knows what step 54 is because it’s so looooooooong).
So, instead of putting you through this pain myself, let’s just break down what LLMs are in 3 key ideas:
- Tokenization
- Transformers
- Processing Language
Tokenization
In ChatGPT, you input a piece of text, and it returns text, right? Well, what’s actually happening is that your text is first converted into tokens.
But what’s a token? You might ask. Well, a token can correspond to a word, a character, or anything we want. Think about it — if you are to send a sentence to a neural network, you didn’t plan on sending actual words, did you?
The input of a neural network is always a number, so you need to convert your text into numbers; this is tokenization.
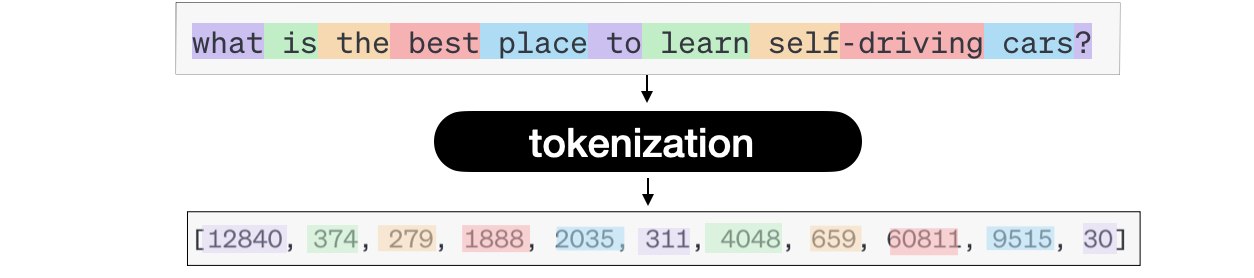
Depending on the model (ChatGPT, LLAMA, etc…), a token can mean different things: a word, a subword, or even a character. We could take the English vocabulary and define these as words or take parts of words (subwords) and handle even more complex inputs. For example, the word « a » could be token 1, and the word « abracadabra » would be token 121.
Transformers
Now that we understand how to convert a sentence into a series of numbers, we can send that series into our neural network! At a high level, we have the following structure:
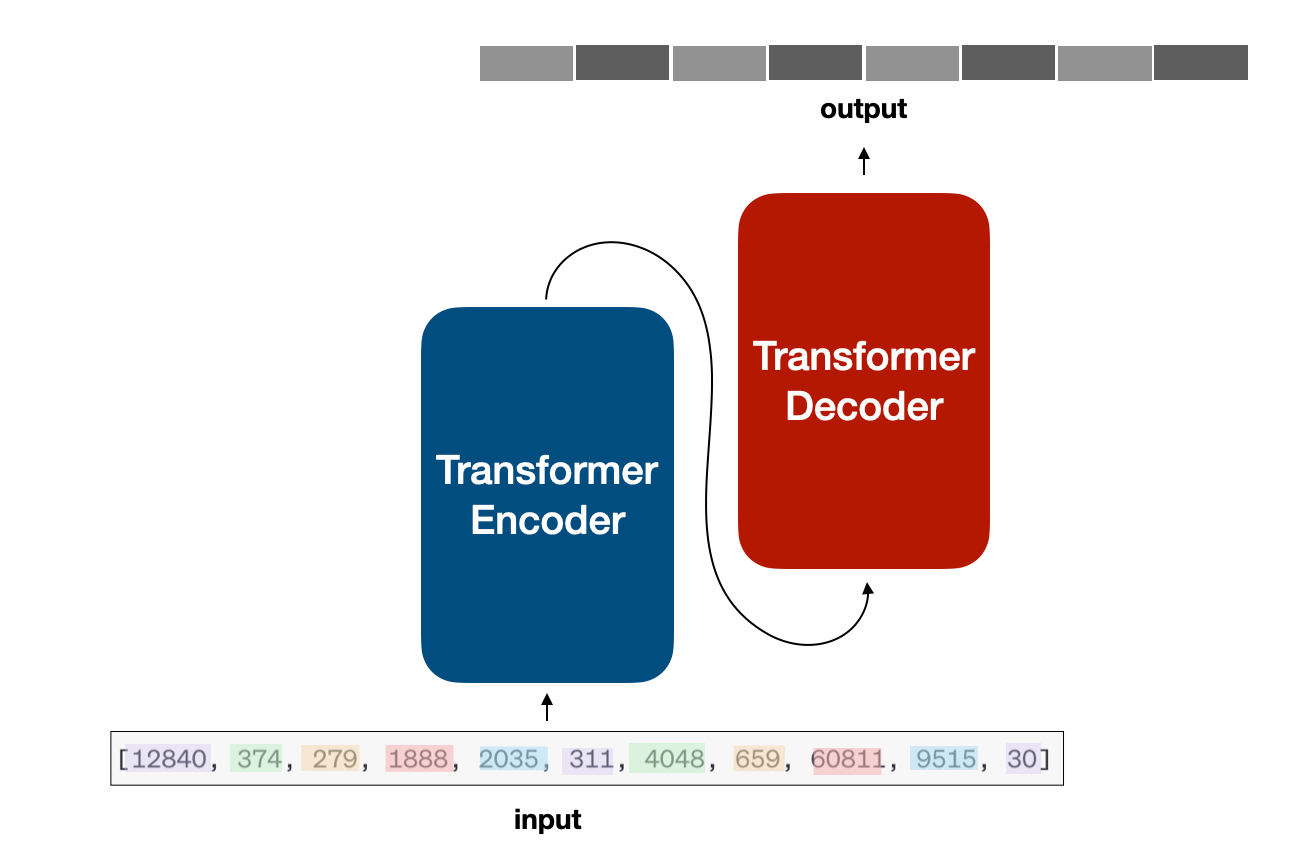
If you start looking around, you will see that some models are based on an encoder-decoder architecture, some others are purely encoder-based, and others, like GPT, are purely decoder-based.
Whatever the case, they all share the core Transformer blocks: multi-head attention, layer normalization, addition and concatenation, blocks, cross-attention, etc…
This is just a series of attention blocks getting you to the output. So how does this word prediction work?
The output/ Next-Word Prediction
The Encoder learns features and understands context… But what does the decoder do? In the case of object detection, the decoder is predicting bounding boxes. In the case of segmentation, the decoder is predicting segmentation masks. What about here?
In our case, the decoder is trying to generate a series of words; we call this task “next-word prediction”.
Of course, it does it similarly by predicting numbers or tokens. This characterizes our full model as shown below,
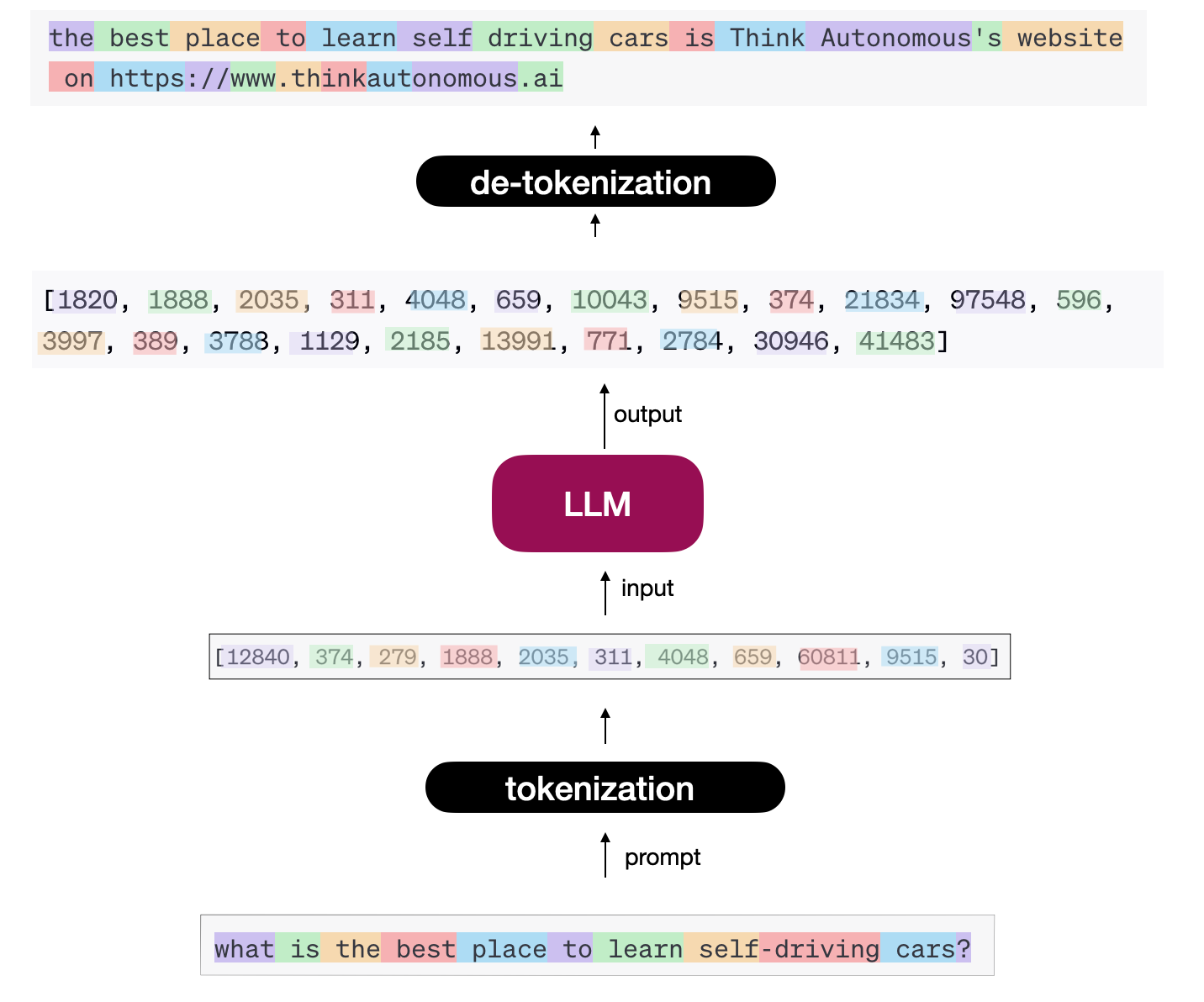
Now, there are many “concepts” that you should learn on top of this intro: everything Transformer and Attention related, but also few-shot learning, pretraining, finetuning, and more…
Ok… but what does it have to do with self-driving cars? I think it’s time to move to stage 2.
Chat-GPT for Self-Driving Cars
The thing is, you’ve already been through the tough part. The rest simply is: “How do I adapt this to autonomous driving?”. Think about it; we have a few modifications to make:
- Our input now becomes either images, sensor data (LiDAR point clouds, RADAR point clouds, etc…), or even algorithm data (lane lines, objects, etc…). All of it is “tokenizable”, as Vision Transformers or Video Vision Transformers do.
- Our Transformer model pretty much remains the same since it only operates on tokens and is independent of the kind of input.
- The output is based on the set of tasks we want to do. It could be explaining what’s happening in the image or could also be a direct driving task like switching lanes.
So, let’s begin with the end:
What self-driving car tasks could LLM solve?
There are many tasks involved in autonomous driving, but not all of them are GPT-isable. The most active research areas in 2023 have been:
- Perception: Based on an input image, describe the environment, number of objects, etc…
- Planning: Based on an image, or a bird-eye view, or the output of perception, describe what we should do (keep driving, yield, etc…)
- Generation: Generate training data, alternate scenarios, and more… using “diffusion”
- Question & Answers: Create a chat interface and ask the LLM to answer questions based on the scenario.
LLMs in Perception
In Perception, the input is a series of images, and the output is usually a set of objects, lanes, etc… In the case of LLMs, we have 3 core tasks: Detection, Prediction, and Tracking. An example with Chat-GPT, when you send it an image and ask to describe what’s going on is shown below:

Other models such as HiLM-D and MTD-GPT can also do this, some work also for videos. Models like PromptTrack, also have the ability to assign unique IDs (this car in front of me is ID #3), similar to a 4D Perception model.
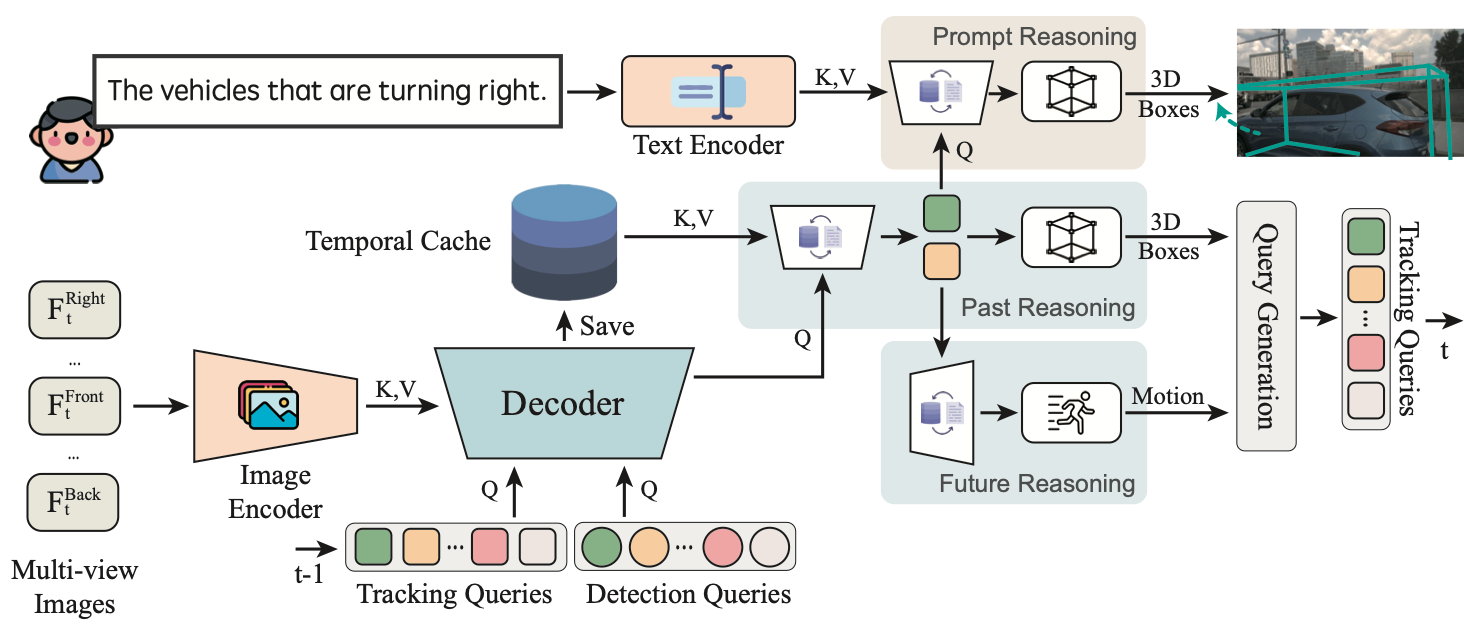
In this model, multi-view images are sent to an Encoder-Decoder network that is trained to predict annotations of objects such as bounding boxes, and attention maps). These maps are then combined with a prompt like ‘find the vehicles that are turning right’.The next block then finds the 3D Bounding Box localization and assigns IDs using a bipartite graph matching algorithm like the Hungarian Algorithm.
This is cool, but this isn’t the “best” application of LLMs so far:
LLMs in Decision Making, Navigation, and Planning
If Chat-GPT can find objects in an image, it should be able to tell you what to do with these objects, shouldn’t it? Well, this is the task of Planning i.e. defining a path from A to B, based on the current perception. While there are numerous models developed for this task, the one that stood out to me was Talk2BEV:
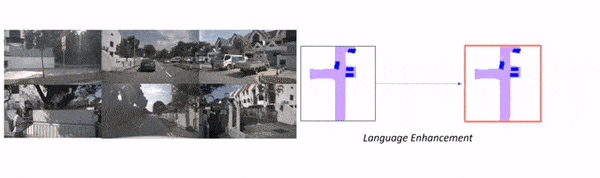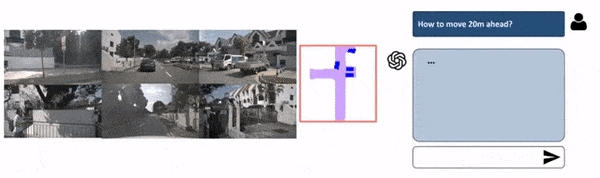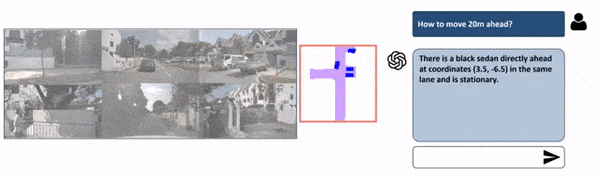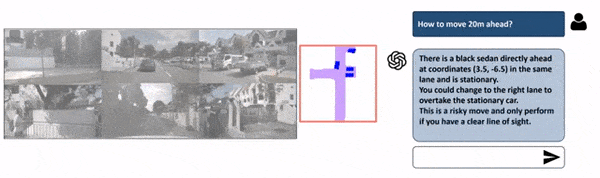
The main difference between models for planning and Perception-only models is that here, we’re going to train the model on human behavior to suggest ideal driving decisions. We’re also going to change the input from multi-view to Bird Eye View since it is much easier to understand.
This model works both with LLaVA and ChatGPT4, and here is a demo of the architecture:

As you can see, this isn’t purely “prompt” based, because the core object detection model stays Bird Eye View Perception, but the LLM is used to “enhance” that output by suggesting to crop some regions, look at specific places, and predict a path. We’re talking about “language enhanced BEV Maps”.
Other models like DriveGPT are trained to send the output of Perception to Chat-GPT and finetune it to output the driving trajectory directly.
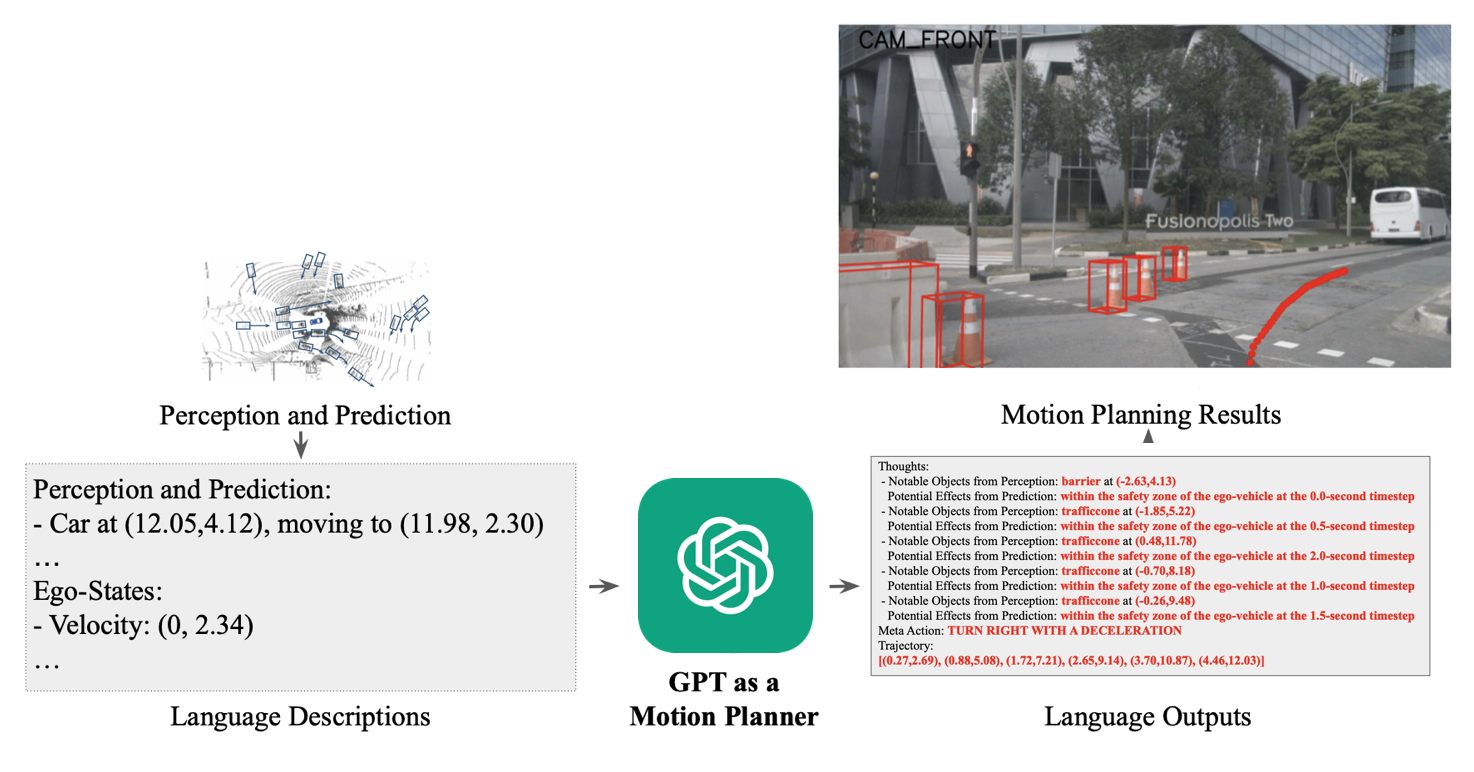
I could go on and on, but I think you get the point. If we summarize, I would say that:
- Inputs are either tokenized images or outputs of Perception algorithm (BEV maps, …)
- We fuse existing models (BEV Perception, Bipartite Matching, …) with language prompts (find the moving cars)
- Changing the task is mainly about changing the data, loss function, and careful finetuning.
The Q&A applications are very similar, so let’s see the last application of LLMs:
LLMs for Image Generation
Ever tried Midjourney and DALL-E? Isn’t it super cool? Yes, and there is MUCH COOLER than this when it comes to autonomous driving. In fact, have you heard of Wayve’s GAIA-1 model? The model takes text and images as input and directly produces videos, like this:

The architecture takes images, actions, and text prompts as input, and then uses a World Model (an understanding of the world and its interactions) to produce a video.
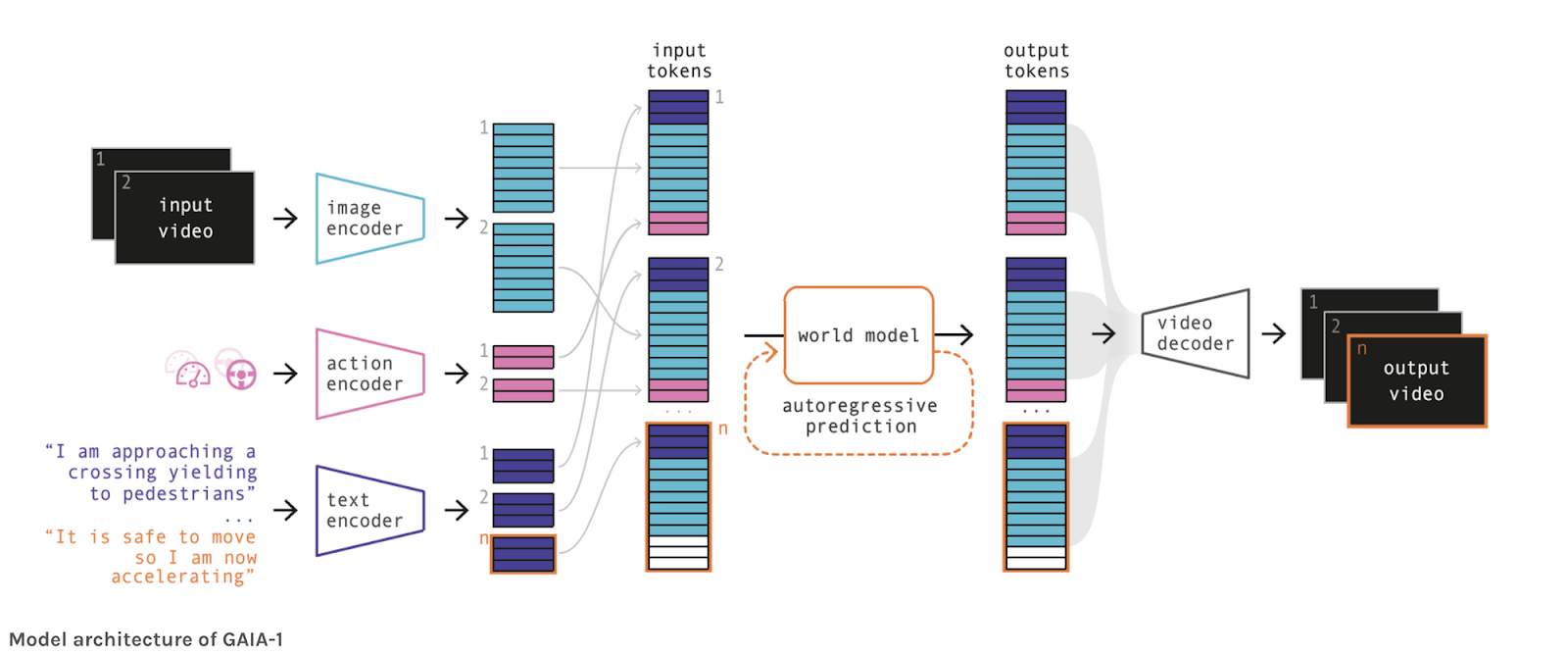
You can find more examples on Wayve’s YouTube channel and this dedicated post.
Similarly, you can see MagicDrive, which takes the output of Perception as input and uses that to generate scenes:
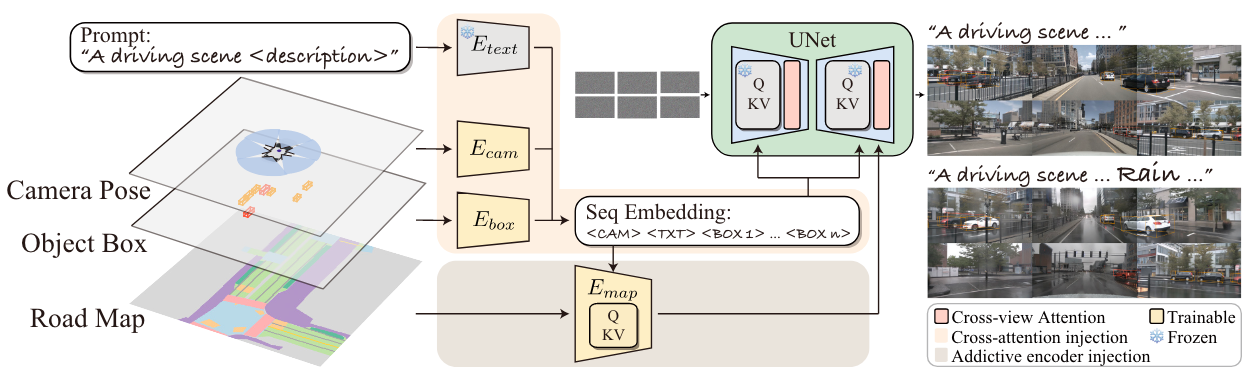
Other models, like Driving Into the Future and Driving Diffusion can directly generate future scenarios based on the current ones. You get the point; we can generate scenes in an infinite way, get more data for our models, and have this endless positive loop.
We’ve just seen 3 prominent families of LLM usage in self-driving cars: Perception, Planning, and Generation. The real question is…
Could we trust LLMs in self-driving cars?
And by this, I mean… What if your model has hallucinations? What if its replies are completely absurd, like ChatGPT sometimes does? I remember, back in my first days in autonomous driving, big groups were already skeptical about Deep Learning, because it wasn’t “deterministic” (as they call it).
We don’t like Black Boxes, which is one of the main reasons End-To-End will struggle to get adopted. Is ChatGPT any better? I don’t think so, and I would even say it’s worse in many ways. However, LLMs are becoming more and more transparent, and the black box problem could eventually be solved.
To answer the question “Can we trust them?”… it’s very early in the research, and I’m not sure someone has really used them “online” — meaning « live », in a car, on the streets, rather than in a headquarter just for training or image generation purpose. I would definitely picture a Grok model on a Tesla someday just for Q&A purposes. So for now, I will give you my coward and safe answer…
It’s too early to tell!
Because it really is. The first wave of papers mentioning LLMs in Self-Driving Cars is from mid-2023, so let’s give it some time. In the meantime, you could start with this survey that shows all the evolutions to date.
Alright, time for the best part of the article…
The LLMs 4 AD Summary
- A Large Language Model (LLM) works in 3 key steps: inputs, transformer, output. The input is a set of tokenized words, the transformer is a classical transformer, and the output task is “next word prediction”.
- In a self-driving car, there are 3 key tasks we can solve with LLMs: Perception (detection, tracking, prediction), Planning (decision making, trajectory generation), and Generation (scene, videos, training data, …).
- In Perception, the main goal is to describe the scene we’re looking at. The input is a set of raw multi-view images, and the Transformer aims to predict 3D bounding boxes. LLMs can also be used to ask for a specific query (“where are the taxis?”).
- In Planning, the main goal is to generate a trajectory for the car to take. The input is a set of objects (output of Perception, BEV Maps, …), and the Transformer uses LLMs to understand context and reason about what to do.
- In Generation, the main goal is to generate a video that corresponds to the prompt used. Models like GAIA-1 have a chat interface, and take as input videos to generate either alternate scenes (rainy, …), or future scenes.
- For now, it’s very early to tell whether this can be used in the long run, but research there is some of the most active in the self-driving car space. It all comes back to the question: “Can we really trust LLMs in general?”
Next Steps
If you want to get started on LLMs for self-driving cars, there are several things you can do:
- ⚠️ Before this, the most important: If you want to keep learning about self-driving cars. I’m talking about self-driving car every day through my private emails. I’m sending many tips and direct content. You should join here.
- ✅ To begin, build an understanding of LLMs for self-driving cars. This is partly done, you can continue to explore the resources I provided in the article.
- ➡️ Second, build skills related to Auto-Encoders and Transformer Networks. My image segmentation series is perfect for this, and will help you understand Transformer Networks with no NLP example, which means it’s for Computer Vision Engineer’s brains.
- ️ ➡️ Then, understand how Bird Eye View Networks works. It might not be mentioned in general LLM courses, but in self-driving cars, Bird Eye View is the central format where we can fuse all the data (LiDARs, cameras, multi-views, …), build maps, and directly create paths to drive. You can do so in my Bird Eye View course (if closed, join my email list to be notified).
- Finally, practice training, finetuning, and running LLMs in self-driving car scenarios. Run repos like Talk2BEV and the others I mentioned in the article. Most of them are open source, but the data can be hard to find. This is noted last, but there isn’t really an order in all of this.
Author Bio
Jérémy Cohen is a self-driving car engineer and founder of Think Autonomous, a platform to help engineers learn about cutting-edge technologies such as self-driving cars and advanced Computer Vision. In 2022, Think Autonomous won the price for Top Global Business of the Year in the Educational Technology Category and Jeremy Cohen was named 2023 40 Under 40 Innovators in Analytics Insight magazine, the largest printed magazine on Artificial Intelligence. You can join 10,000 engineers reading his private daily emails on self-driving cars here.
Citation
For attribution in academic contexts or books, please cite this work as
Jérémy Cohen, "Car-GPT: Could LLMs finally make self-driving cars happen?", The Gradient, 2024.BibTeX citation:
@article{cohen2024cargpt,
author = {Jérémy Cohen},
title = {Car-GPT: Could LLMs finally make self-driving cars happen?},
journal = {The Gradient},
year = {2024},
howpublished = {url{https://thegradient.pub/car-gpt},
}