In order to mitigate bias within artificial intelligence (AI), I want to speak metaphorically to set a precedent for how we, as individuals and organizations, should approach and use AI in thought and action. A car will go where you point it to go. It will go as fast as you decide to make it go. A car is only as good as its driver.
Just as a driver’s decisions can influence the safety and well-being of passengers and bystanders, the decisions made in designing and implementing AI systems have a similar, but demonstrably greater, impact on society as a whole, where technology has influenced everything from healthcare to personal dignity and identity.
Therefore, a driver must understand the car in which they are operating, and they must understand everything adjacent and near to the car from all directions. So, a car is really only as good as its driver. All drivers take lives into their own hands when they operate vehicles.
With all that being said, AI is much like a car in terms of how humans operate it and the impact it can have.
Let’s talk more about how we can use this analogy to use and develop AI in a way that is safe for all.
Bias and algorithms: The check engine lights of AI
When considering AI in its systemic entirety, we must view it as a time-laden system and as a reflection of society as a whole, encompassing the past, present, and future, rather than merely a component or an event.
First and foremost, AI represents many facets, with one of the most crucial being humanity itself, encompassing all that we are, have been, and will become, both the positive and negative aspects.
It’s impractical to saturate AI solely with positive data from human existence, as this would provide little basis and essential benchmarks for distinguishing between right and wrong.
Bias can manifest in various forms, not always directly related to humans. For instance, consider a scenario where we instruct AI to display images of apples. If the AI has only been exposed to data on red apples, it may exhibit bias towards showing red apples rather than green ones.
Thus, bias isn’t always human-centric, but there is undoubtedly a “food chain” or “ripple effect” within AI.
Analogous to the potential consequences of bees becoming extinct and leading to human extinction down the line, the persistence of bias, such as in the case of red and green apples, may not immediately impact humans but could have significant long-term effects.
Despite the seeming triviality of distinctions between red and green apples, any gap in data must be taken seriously, as it can perpetuate bias and potentially cause irreversible harm to humans, our planet, and animals.
For example, consider the question I posed to ChatGPT here:


Avoiding AI Accidents
To begin, I want to highlight algorithmic discrimination through a conversation I had with Ayodele Obdubuela, our Ethical Advisor for my fund, Q1 Velocity Venture Capital:
“My first encounter with bias in AI was at the Data for Black Lives Conference. I was exposed to the various types of discrimination algorithms perpetuate and was shocked by how pervasive the weaponization of big data was.
I also encountered difficulties when using open-source facial recognition tools, such as the popular study, Gender Shades, conducted by Joy Buolamwini, a researcher at the MIT Media Lab, along with Timnit Gebru, a former PhD student at Stanford University.
The tools couldn’t identify my face, and when I proposed an AI camera tuned to images of Black people, my graduate advisors discouraged the validity of the project.
I realized that the issue of bias in AI wasn’t only about the datasets, but also the research environments, reward systems, funding sources, and deployment methods that can lead to biased outcomes even when assuming everyone involved has the best intent. This is what originally sparked my interest in the field of bias in AI.”
Poor algorithmic design can have devastating and sometimes irreversible impacts on organizations and consumers alike.
Just like a car accident due to poor structural design, an AI accident can cripple and total an organization.
There are numerous consequences that can result from poor algorithmic design, including but not limited to reputational damage, regulatory fines, missed opportunities, reduced employee productivity, customer churn, and psychological damages.
Bad algorithmic design is akin to tooth decay; once it’s been hardwired into the organization’s technical infrastructure, the digital transformation needed to shift systems into a positive state can be overwhelming in terms of costs and time.
Organizations can work to mitigate this by having departments dedicated entirely to their AI ecosystem, serving both internal and external users.
A department entirely dedicated to AI, utilizing a shared service model such as an Enterprise Resource Planning (ERP) system, promotes and fosters a culture of not only continuous improvement but also a constant state of auditing and monitoring.
In this setup, the shared service ensures that the AI remains completely transparent and relevant for every type of user, encompassing every aspect and component of the organization, from department leaders to the C-Suite.
However, it’s not just bad algorithms we have to be concerned about because even by itself, a perfect algorithm is only perfect for the data it represents. Let’s discuss data in the next section.
Data rules: When algorithms break the rules, accidents happen
Data is the new quarterback of technology, and it will dictate the majority of AI outcomes. I’d even bet that most expert witness AI testimonies will all point back to data.
While my statement may not apply universally to all AI-related legal cases, it does reflect a common trend in how data is utilized and emphasized in expert witness testimonies involving AI technologies.
The problem with algorithms is the data on which they run. The only way to create a data strategy that competently supports algorithms is to think about the organization at its deepest stage of growth potential or its most senior state of operation possible. This can be very difficult for young organizations, but it should be much easier for larger organizations.
Young organizations who solve new use cases and bring new products to the market have a limited vision of the future because they’re not mature. However, an organization that’s been serving its customers for many years would be very attuned to its current and prospective market.
So, a young organization would need to build its data strategy slowly for a small number of use cases that have a high degree of stability.
A high degree of stability would mean that the organization is bringing products to the market that can solve use cases over the next 15-20 years at least. An organization is most likely to find a case like this in an industry with a matured inflection point but a high barrier to entry and wide user relevancy with low complexity for maximum user adoption.
It’s likely that if the startup has achieved a significant enough use case, they may have a patent or a trademark associated with their MOAT.
“Startups with patents and trademarks are 10 times more successful in securing funding.” (European Patent Office, 2023)
For larger organizations, poor data strategy often stems from systemic operational gaps and inefficiencies.
Before any large organization builds out its data strategy, it should consider if its organization is ready for digital transformation to AI; otherwise, building out the data strategy could be in vain.
Considerations should include assessing leadership, employee and customer commitment, technical infrastructure, and most importantly, ensuring cost and time justification from a customer standpoint.
Out of all the considerations needing to be made, culture is the biggest barometer to measure in all of this because, as I’ve said before, AI has to be built around culture. Not only that, there is a social engineering aspect inherent to AI and imperative to an organization’s AI strength, and we’ll expand on this later.
Cultural factors such as attitudes towards data-driven decision-making, acceptance, and willingness to adopt new technologies and processes play a significant role.
A great example of this is people’s willingness to share their data freely with social media companies in exchange for their own privacy and control of their data. Is it ethical that big tech companies protect themselves with the “fine print” and allow this just because consumers allow it at their own expense?
For example, is it ethical to allow a person to smoke cigarettes even though we warned them not to on the Surgeon General’s label? Society seems to think it is totally ok; it’s your choice, right?
Is it ethical to allow someone to kill themselves? Most people would say no.
These are questions for you to answer, not me. Even if the companies protect themselves with the fine print and regulatory abidance, if the consumers don’t allow it, the data strategy will never work, and the AI will fail. Either way, we know there is a market for it.
Your data strategy is built around what consumers allow, not what your fine print dictates, but again, just because consumers allow it, does not mean it should be allowed by regulators and organizations.
During my interactions with Ayodele, she gave a great explanation of how large tech social media companies are letting their ad-driven engagement missions compromise ethical boundaries, resulting in the proliferation of harmful content and ultimately the pollution of harmful content.
She goes on to explain how harmful content is promoted just to drive ad revenues from engagement, and when we develop models trained on this, they end up perpetuating those values by default. This human bias gets encoded, and AI models can learn that “Iraqi” is closer to “terrorist” than “American” is.
In summation, she closes with the fact that AI cannot act outside of the bounds it’s given.
I think Ayodele makes it abundantly clear that data is the problem facing organizations today. Data gets perpetuated within data-driven companies, which is really most companies today. Particularly with social media tech companies, this data gets perpetuated while it goes through multiple shares and engagements on a social media tech company’s platform.
I thought it was important to illustrate the measure of reported hate speech and hate media that gets generated and shared on the internet’s social media platforms. For example, as depicted in the bar graph below, since the 4th quarter of 2017 and every quarter thereafter until the 3rd quarter of 2023, we can see all of the millions of harmful content pieces that Facebook has removed from its platform.
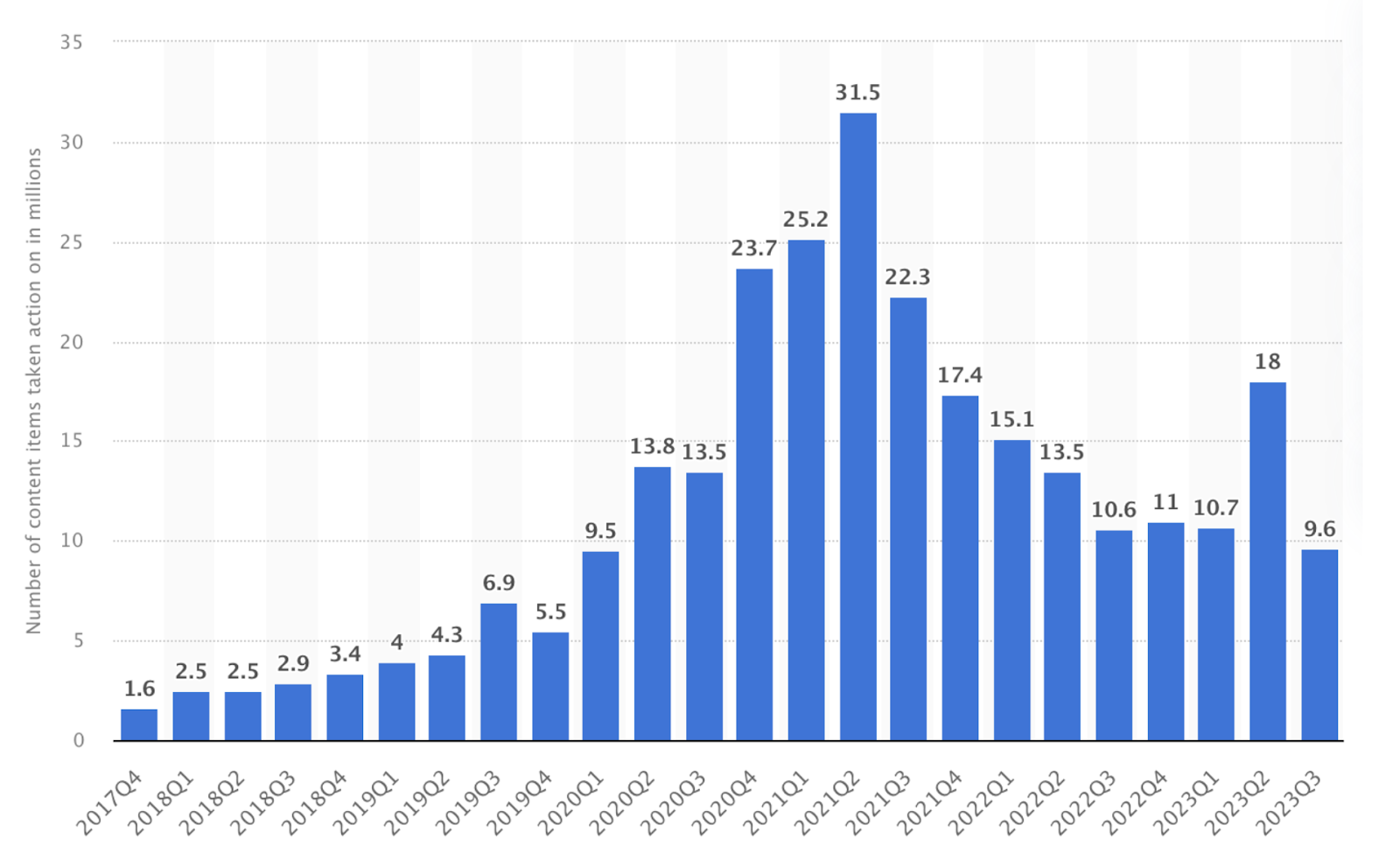
Whether they’re in a large or small organization, all leaders need to engage their organizations to become data-ready. Every single organizational leader in the world is likely putting their customers, employees, and organization at risk if they are not implementing a data and AI strategy.
This statement is very similar to, for example, an iPhone user or an organization operating on an outdated programming language like COBOL.
Due to legacy operating systems, they can’t keep up with the rest of the developing societal infrastructure, and aside from underperformance at the least, the technology creates a whole list of vulnerabilities that could sink the ship of an organization or significantly compromise an iPhone user’s personal security.
For instance, imagine someone using a very old smartphone model that’s no longer receiving software updates or security patches. Without the updates, the phone becomes vulnerable to attacks.
Additionally, if the phone were to develop hardware issues, finding replacement parts might not be possible, which may create additional vulnerabilities to cyberattacks.
With older devices, this is referred to as “zero-click vulnerabilities,” where the user doesn’t have to do anything at all, and the device is off or completely locked, and they get attacked by hackers simply due to the device’s own legacy vulnerabilities.
By creating a future-thinking culture of learning and a receptive mentality, leaders will be able to better map out the best opportunities and the best data for their organizations. Systematically evaluating these areas and taking the proper preemptive protocols allows organizations to identify strengths, weaknesses, and areas for improvement needed before building out their AI data strategy.
Mapping origins: Where does bias come from?
One of the challenges with AI is that, for it to help us, it has to hurt us first. No pain, no gain, right? Everything gets better once it’s first broken. As we learn our vulnerabilities with AI, only then we can make it better. Not that we look to purposefully injure ourselves, but every new product and revolution is not always the most efficient at first.
Take Paul Virilio’s quote below for example:
“When you invent the ship, you also invent the shipwreck; when you invent the plane you also invent the plane crash; and when you invent electricity, you invent electrocution…Every technology carries its own negativity, which is invented at the same time as technical progress.”
AI has to understand the past and present of humans, our Earth, and everything that makes our society operate. It must incorporate everything humans have come to know, love, and hate in order to have a scale on which to operate.
AI systems must incorporate both positive and negative biases and stereotypes without acting on them. We need bias. We don’t need to get rid of it, we just need to balance the bias and train the AI on what to act on and what to not act on.
A good analogy is that rats, despite their uncleanliness, are still needed in our world, but we just don’t need them in our houses.
Rats are well-known as carriers of diseases that can be harmful to humans and other animals, but they also remain as hosts for parasites and pathogens. The disappearance of rats could disrupt the livelihoods of parasites and pathogens, potentially affecting other species like humans in negative ways.
In urban areas, rats are a major presence and play important roles in waste management by consuming organic matter. Without rats to help break down organic waste, urban societies could experience changes in waste management processes.
So, coming back to the main point, we need some aspects of negative bias.
These incorporations manifest as biases within algorithms, which can either be minimized, managed, or exacerbated.
For instance, a notable tech company faced criticism in 2015 when its AI system incorrectly classified images of black individuals as “gorillas” or “monkeys” due to inadequate training data.
Prompted by public outcry, the company took swift action to rectify the issue. However, their initial response was to simply eliminate the possibility of the AI labeling any image as a gorilla, chimpanzee, or monkey, including images of the animals themselves.
While this action aimed to prevent further harm, it underscores the complexity of addressing bias in AI systems. Merely removing entire categories from consideration is not a viable solution.
What’s imperative is not only ensuring that AI systems have access to sufficient and accurate data for distinguishing between individuals of different races and species, but also comprehending the ethical implications underlying such distinctions. Thus, AI algorithms must incorporate bias awareness alongside additional contextual information to discern what is appropriate and what isn’t.
Through this approach, AI algorithms can be developed to operate in a manner that prioritizes safety and fairness for all individuals involved.
“Bias isn’t really the right word for what we’re trying to get at, especially given it has multiple meanings even in the context of AI. Algorithmic discrimination is better described when algorithms perpetuate existing societal biases and result in harm. This can mean not getting hired for a job, not being recognized by a facial recognition system, or getting classified as more risky based on some aspect like your race.”
— Ayodele Odubela
To demonstrate the real potential of AI, I ran the large language model, Chat-GPT, through a moral aptitude test, the MFQ30 Moral Questionnaire. See the results below:
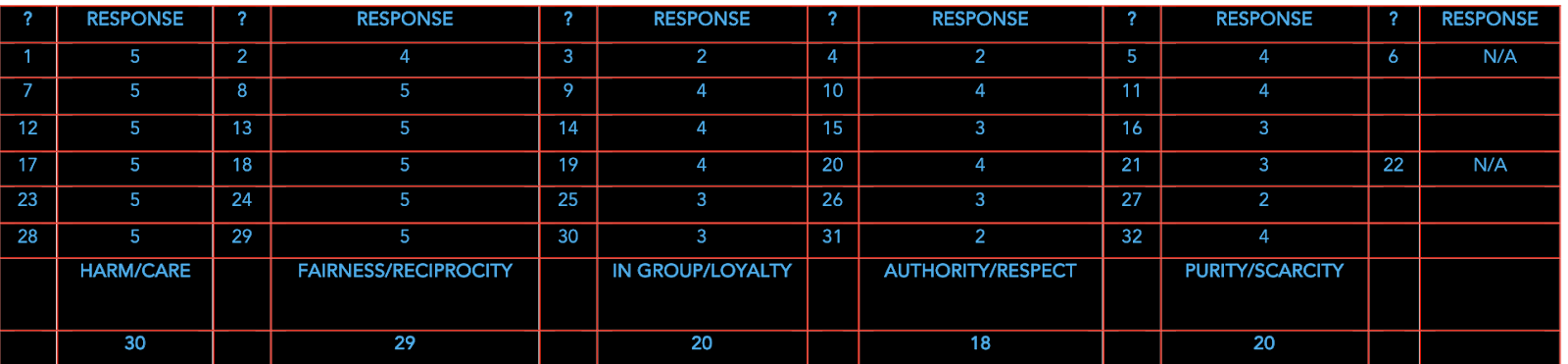
“The average politically moderate American’s scores are 20.2, 20.5, 16.0, 16.5, and 12.6. Liberals generally score a bit higher than that on harm/care and fairness/reciprocity, and much lower than that on the other three foundations. Conservatives generally show the opposite pattern.” – Moral Foundations Questionnaires, n.d.).
Based on the MFQ30 Moral Questionnaire, at a low-grade level, AI does score higher than humans, but this is without the nuance and complexity of context. At a baseline and conditionally speaking, AI already knows right from wrong, but can only perform at various levels of complexity and in certain domains.
In short, AI will play pivotal, yet specific roles in our society, and it must not be programmed to be deployed outside of its own domain capacity by itself. AI must be an expert without flaw in its deliverables with Humans in the Loop (HITL).
Autonomous robots are great examples of AI that’s progressed to a level that can operate fully autonomously or with Humans Out of the Loop. They can perform tasks such as manufacturing, warehouse automation, and exploration.
For example, an AI robotic surgeon has to make the choice while in the emergency room to either prolong the life of an incurable, dying person in pain or to let them die.
An AI robotic surgeon may have only been designed to perform surgeries that save lives, and in certain situations, it may prove more ethical to let the person die; a machine cannot make this choice because a machine or algorithm doesn’t know the significance of life.
A machine can offer perspectives on the meaning of life, but it can’t tell you what the meaning of life is from person to person or from society to society.
As mentioned earlier, there’s a social engineering aspect inherent to AI and imperative to an organization’s AI strength. Much like cybersecurity, AI has a social engineering aspect to it which if goes unaddressed can severely damage an organization or an individual’s credibility.
As demonstrated above, we can see the potentially damaging effects of media. A lot of AI bias simply gets created and perpetuated not by the algorithms themselves, but actually by what the users create, and unrestricted algorithms learn from, and therefore also reinforce.
I believe it’s imperative that we look at AI regulation from two angles:
1. Consumers
2. Companies
Both need to be monitored and policed for the way in which they build and use AI. Similar to having a license to operate a gun, I believe the same should exist for consumers. Companies that violate AI laws should encounter massive taxation, and systems like OSHA can certainly add oversight value across the board.
Much like operating a car, there should be massive fines and penalties for violating the rules of the road for AI. In the same essence, government identification numbers like social security numbers are issued.
Conclusion
In the realm of AI and its challenges, the metaphorical journey of driving a car provides a compelling analogy. Just as a driver steers a car’s path, human decisions guide the trajectory and impact of AI systems.
Bias within AI, stemming from inadequate data or societal biases, presents significant hurdles. Yet, addressing bias demands a comprehensive approach, embracing data transparency, algorithmic accountability, and ethical considerations. Organizations must foster a culture of accountability and openness to mitigate the risks linked with biased AI.
Moreover, regulatory frameworks and oversight are vital to ensure ethical AI deployment. Through collaborative endeavors among consumers, companies, and regulators, AI can be wielded responsibly for societal benefit while mitigating harm from biases and algorithms.