Mathematics has always posed a significant challenge for AI models. Mastering math requires complex reasoning skills, and for AI, this task is anything but straightforward. That creates a huge problem given the importance of mathematical proficiency for professional, personal, and academic success. Despite their remarkable abilities,…
What do we know about the economics of AI?

For all the talk about artificial intelligence upending the world, its economic effects remain uncertain. There is massive investment in AI but little clarity about what it will produce.
Examining AI has become a significant part of Nobel-winning economist Daron Acemoglu’s work. An Institute Professor at MIT, Acemoglu has long studied the impact of technology in society, from modeling the large-scale adoption of innovations to conducting empirical studies about the impact of robots on jobs.
In October, Acemoglu also shared the 2024 Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel with two collaborators, Simon Johnson PhD ’89 of the MIT Sloan School of Management and James Robinson of the University of Chicago, for research on the relationship between political institutions and economic growth. Their work shows that democracies with robust rights sustain better growth over time than other forms of government do.
Since a lot of growth comes from technological innovation, the way societies use AI is of keen interest to Acemoglu, who has published a variety of papers about the economics of the technology in recent months.
“Where will the new tasks for humans with generative AI come from?” asks Acemoglu. “I don’t think we know those yet, and that’s what the issue is. What are the apps that are really going to change how we do things?”
What are the measurable effects of AI?
Since 1947, U.S. GDP growth has averaged about 3 percent annually, with productivity growth at about 2 percent annually. Some predictions have claimed AI will double growth or at least create a higher growth trajectory than usual. By contrast, in one paper, “The Simple Macroeconomics of AI,” published in the August issue of Economic Policy, Acemoglu estimates that over the next decade, AI will produce a “modest increase” in GDP between 1.1 to 1.6 percent over the next 10 years, with a roughly 0.05 percent annual gain in productivity.
Acemoglu’s assessment is based on recent estimates about how many jobs are affected by AI, including a 2023 study by researchers at OpenAI, OpenResearch, and the University of Pennsylvania, which finds that about 20 percent of U.S. job tasks might be exposed to AI capabilities. A 2024 study by researchers from MIT FutureTech, as well as the Productivity Institute and IBM, finds that about 23 percent of computer vision tasks that can be ultimately automated could be profitably done so within the next 10 years. Still more research suggests the average cost savings from AI is about 27 percent.
When it comes to productivity, “I don’t think we should belittle 0.5 percent in 10 years. That’s better than zero,” Acemoglu says. “But it’s just disappointing relative to the promises that people in the industry and in tech journalism are making.”
To be sure, this is an estimate, and additional AI applications may emerge: As Acemoglu writes in the paper, his calculation does not include the use of AI to predict the shapes of proteins — for which other scholars subsequently shared a Nobel Prize in October.
Other observers have suggested that “reallocations” of workers displaced by AI will create additional growth and productivity, beyond Acemoglu’s estimate, though he does not think this will matter much. “Reallocations, starting from the actual allocation that we have, typically generate only small benefits,” Acemoglu says. “The direct benefits are the big deal.”
He adds: “I tried to write the paper in a very transparent way, saying what is included and what is not included. People can disagree by saying either the things I have excluded are a big deal or the numbers for the things included are too modest, and that’s completely fine.”
Which jobs?
Conducting such estimates can sharpen our intuitions about AI. Plenty of forecasts about AI have described it as revolutionary; other analyses are more circumspect. Acemoglu’s work helps us grasp on what scale we might expect changes.
“Let’s go out to 2030,” Acemoglu says. “How different do you think the U.S. economy is going to be because of AI? You could be a complete AI optimist and think that millions of people would have lost their jobs because of chatbots, or perhaps that some people have become super-productive workers because with AI they can do 10 times as many things as they’ve done before. I don’t think so. I think most companies are going to be doing more or less the same things. A few occupations will be impacted, but we’re still going to have journalists, we’re still going to have financial analysts, we’re still going to have HR employees.”
If that is right, then AI most likely applies to a bounded set of white-collar tasks, where large amounts of computational power can process a lot of inputs faster than humans can.
“It’s going to impact a bunch of office jobs that are about data summary, visual matching, pattern recognition, et cetera,” Acemoglu adds. “And those are essentially about 5 percent of the economy.”
While Acemoglu and Johnson have sometimes been regarded as skeptics of AI, they view themselves as realists.
“I’m trying not to be bearish,” Acemoglu says. “There are things generative AI can do, and I believe that, genuinely.” However, he adds, “I believe there are ways we could use generative AI better and get bigger gains, but I don’t see them as the focus area of the industry at the moment.”
Machine usefulness, or worker replacement?
When Acemoglu says we could be using AI better, he has something specific in mind.
One of his crucial concerns about AI is whether it will take the form of “machine usefulness,” helping workers gain productivity, or whether it will be aimed at mimicking general intelligence in an effort to replace human jobs. It is the difference between, say, providing new information to a biotechnologist versus replacing a customer service worker with automated call-center technology. So far, he believes, firms have been focused on the latter type of case.
“My argument is that we currently have the wrong direction for AI,” Acemoglu says. “We’re using it too much for automation and not enough for providing expertise and information to workers.”
Acemoglu and Johnson delve into this issue in depth in their high-profile 2023 book “Power and Progress” (PublicAffairs), which has a straightforward leading question: Technology creates economic growth, but who captures that economic growth? Is it elites, or do workers share in the gains?
As Acemoglu and Johnson make abundantly clear, they favor technological innovations that increase worker productivity while keeping people employed, which should sustain growth better.
But generative AI, in Acemoglu’s view, focuses on mimicking whole people. This yields something he has for years been calling “so-so technology,” applications that perform at best only a little better than humans, but save companies money. Call-center automation is not always more productive than people; it just costs firms less than workers do. AI applications that complement workers seem generally on the back burner of the big tech players.
“I don’t think complementary uses of AI will miraculously appear by themselves unless the industry devotes significant energy and time to them,” Acemoglu says.
What does history suggest about AI?
The fact that technologies are often designed to replace workers is the focus of another recent paper by Acemoglu and Johnson, “Learning from Ricardo and Thompson: Machinery and Labor in the Early Industrial Revolution — and in the Age of AI,” published in August in Annual Reviews in Economics.
The article addresses current debates over AI, especially claims that even if technology replaces workers, the ensuing growth will almost inevitably benefit society widely over time. England during the Industrial Revolution is sometimes cited as a case in point. But Acemoglu and Johnson contend that spreading the benefits of technology does not happen easily. In 19th-century England, they assert, it occurred only after decades of social struggle and worker action.
“Wages are unlikely to rise when workers cannot push for their share of productivity growth,” Acemoglu and Johnson write in the paper. “Today, artificial intelligence may boost average productivity, but it also may replace many workers while degrading job quality for those who remain employed. … The impact of automation on workers today is more complex than an automatic linkage from higher productivity to better wages.”
The paper’s title refers to the social historian E.P Thompson and economist David Ricardo; the latter is often regarded as the discipline’s second-most influential thinker ever, after Adam Smith. Acemoglu and Johnson assert that Ricardo’s views went through their own evolution on this subject.
“David Ricardo made both his academic work and his political career by arguing that machinery was going to create this amazing set of productivity improvements, and it would be beneficial for society,” Acemoglu says. “And then at some point, he changed his mind, which shows he could be really open-minded. And he started writing about how if machinery replaced labor and didn’t do anything else, it would be bad for workers.”
This intellectual evolution, Acemoglu and Johnson contend, is telling us something meaningful today: There are not forces that inexorably guarantee broad-based benefits from technology, and we should follow the evidence about AI’s impact, one way or another.
What’s the best speed for innovation?
If technology helps generate economic growth, then fast-paced innovation might seem ideal, by delivering growth more quickly. But in another paper, “Regulating Transformative Technologies,” from the September issue of American Economic Review: Insights, Acemoglu and MIT doctoral student Todd Lensman suggest an alternative outlook. If some technologies contain both benefits and drawbacks, it is best to adopt them at a more measured tempo, while those problems are being mitigated.
“If social damages are large and proportional to the new technology’s productivity, a higher growth rate paradoxically leads to slower optimal adoption,” the authors write in the paper. Their model suggests that, optimally, adoption should happen more slowly at first and then accelerate over time.
“Market fundamentalism and technology fundamentalism might claim you should always go at the maximum speed for technology,” Acemoglu says. “I don’t think there’s any rule like that in economics. More deliberative thinking, especially to avoid harms and pitfalls, can be justified.”
Those harms and pitfalls could include damage to the job market, or the rampant spread of misinformation. Or AI might harm consumers, in areas from online advertising to online gaming. Acemoglu examines these scenarios in another paper, “When Big Data Enables Behavioral Manipulation,” forthcoming in American Economic Review: Insights; it is co-authored with Ali Makhdoumi of Duke University, Azarakhsh Malekian of the University of Toronto, and Asu Ozdaglar of MIT.
“If we are using it as a manipulative tool, or too much for automation and not enough for providing expertise and information to workers, then we would want a course correction,” Acemoglu says.
Certainly others might claim innovation has less of a downside or is unpredictable enough that we should not apply any handbrakes to it. And Acemoglu and Lensman, in the September paper, are simply developing a model of innovation adoption.
That model is a response to a trend of the last decade-plus, in which many technologies are hyped are inevitable and celebrated because of their disruption. By contrast, Acemoglu and Lensman are suggesting we can reasonably judge the tradeoffs involved in particular technologies and aim to spur additional discussion about that.
How can we reach the right speed for AI adoption?
If the idea is to adopt technologies more gradually, how would this occur?
First of all, Acemoglu says, “government regulation has that role.” However, it is not clear what kinds of long-term guidelines for AI might be adopted in the U.S. or around the world.
Secondly, he adds, if the cycle of “hype” around AI diminishes, then the rush to use it “will naturally slow down.” This may well be more likely than regulation, if AI does not produce profits for firms soon.
“The reason why we’re going so fast is the hype from venture capitalists and other investors, because they think we’re going to be closer to artificial general intelligence,” Acemoglu says. “I think that hype is making us invest badly in terms of the technology, and many businesses are being influenced too early, without knowing what to do. We wrote that paper to say, look, the macroeconomics of it will benefit us if we are more deliberative and understanding about what we’re doing with this technology.”
In this sense, Acemoglu emphasizes, hype is a tangible aspect of the economics of AI, since it drives investment in a particular vision of AI, which influences the AI tools we may encounter.
“The faster you go, and the more hype you have, that course correction becomes less likely,” Acemoglu says. “It’s very difficult, if you’re driving 200 miles an hour, to make a 180-degree turn.”
Arik Solomon, Co-Founder & CEO of Cypago – Interview Series
Arik Solomon, Co-Founder and CEO of Cypago, is on a mission to eliminate the hassle of compliance for businesses. Cypago’s Cyber GRC Automation Platform transforms the traditionally manual, time-consuming process of meeting security standards into an efficient, AI-driven workflow. By integrating with existing software stacks, Cypago…
Utilizing AI to Predict and Prevent Internet Outages
Seamless user experience is the service benchmark for any internet provider as the demand for fewer service disruptions and greater reliable connection grows. To address this need, artificial intelligence (AI) has emerged as an evolving technology that ensures improved service across regions. How Does AI Improve…
AlphaQubit: Solving Quantum Computing’s Most Pressing Challenge
Quantum computing has the potential to change many industries, from cryptography to drug discovery. But scaling these systems is a challenging task. As quantum computers grow, they face more errors and noise that can disrupt the calculations. To address this, DeepMind and Quantum AI introduced AlphaQubit,…
Study: Browsing negative content online makes mental health struggles worse

People struggling with their mental health are more likely to browse negative content online, and in turn, that negative content makes their symptoms worse, according to a series of studies by researchers at MIT.
The group behind the research has developed a web plug-in tool to help those looking to protect their mental health make more informed decisions about the content they view.
The findings were outlined in an open-access paper by Tali Sharot, an adjunct professor of cognitive neurosciences at MIT and professor at University College London, and Christopher A. Kelly, a former visiting PhD student who was a member of Sharot’s Affective Brain Lab when the studies were conducted, who is now a postdoc at Stanford University’s Institute for Human Centered AI. The findings were published Nov. 21 in the journal Nature Human Behavior.
“Our study shows a causal, bidirectional relationship between health and what you do online. We found that people who already have mental health symptoms are more likely to go online and more likely to browse for information that ends up being negative or fearful,” Sharot says. “After browsing this content, their symptoms become worse. It is a feedback loop.”
The studies analyzed the web browsing habits of more than 1,000 participants by using natural language processing to calculate a negative score and a positive score for each web page visited, as well as scores for anger, fear, anticipation, trust, surprise, sadness, joy, and disgust. Participants also completed questionnaires to assess their mental health and indicated their mood directly before and after web-browsing sessions. The researchers found that participants expressed better moods after browsing less-negative web pages, and participants with worse pre-browsing moods tended to browse more-negative web pages.
In a subsequent study, participants were asked to read information from two web pages randomly selected from either six negative webpages or six neutral pages. They then indicated their mood levels both before and after viewing the pages. An analysis found that participants exposed to negative web pages reported to be in a worse mood than those who viewed neutral pages, and then subsequently visited more-negative pages when asked to browse the internet for 10 minutes.
“The results contribute to the ongoing debate regarding the relationship between mental health and online behavior,” the authors wrote. “Most research addressing this relationship has focused on the quantity of use, such as screen time or frequency of social media use, which has led to mixed conclusions. Here, instead, we focus on the type of content browsed and find that its affective properties are causally and bidirectionally related to mental health and mood.”
To test whether intervention could alter web-browsing choices and improve mood, the researchers provided participants with search engine results pages with three search results for each of several queries. Some participants were provided labels for each search result on a scale of “feel better” to “feel worse.” Other participants were not provided with any labels. Those who were provided with labels were less likely to choose negative content and more likely to choose positive content. A followup study found that those who viewed more positive content reported a significantly better mood.
Based on these findings, Sharot and Kelly created a downloadable plug-in tool called “Digital Diet” that offers scores for Google search results in three categories: emotion (whether people find the content positive or negative, on average), knowledge (to what extent information on a webpage helps people understand a topic, on average), and actionability (to what extent information on a webpage is useful on average). MIT electrical engineering and computer science graduate student Jonatan Fontanez ’24, a former undergraduate researcher from MIT in Sharot’s lab, also contributed to the development of the tool. The tool was introduced publicly this week, along with the publication of the paper in Nature Human Behavior.
“People with worse mental health tend to seek out more-negative and fear-inducing content, which in turn exacerbates their symptoms, creating a vicious feedback loop,” Kelly says. “It is our hope that this tool can help them gain greater autonomy over what enters their minds and break negative cycles.”
Chromia’s Asgard upgrade launches: “New era for DeFi and AI” – AI News
The Chromia blockchain development team has announced the successful completion of its Asgard mainnet upgrade that introduces new features and capabilities for the platform. The new features enhance the overall capacity of the Layer 1 blockchain and add specialised capabilities for users. The Asgard mainnet upgrade…
Amazon Bedrock gains new AI models, tools, and features
Amazon Web Services (AWS) has announced improvements to bolster Bedrock, its fully managed generative AI service. The updates include new foundational models from several AI pioneers, enhanced data processing capabilities, and features aimed at improving inference efficiency. Dr Swami Sivasubramanian, VP of AI and Data at…
Want to design the car of the future? Here are 8,000 designs to get you started.
Car design is an iterative and proprietary process. Carmakers can spend several years on the design phase for a car, tweaking 3D forms in simulations before building out the most promising designs for physical testing. The details and specs of these tests, including the aerodynamics of a given car design, are typically not made public. Significant advances in performance, such as in fuel efficiency or electric vehicle range, can therefore be slow and siloed from company to company.
MIT engineers say that the search for better car designs can speed up exponentially with the use of generative artificial intelligence tools that can plow through huge amounts of data in seconds and find connections to generate a novel design. While such AI tools exist, the data they would need to learn from have not been available, at least in any sort of accessible, centralized form.
But now, the engineers have made just such a dataset available to the public for the first time. Dubbed DrivAerNet++, the dataset encompasses more than 8,000 car designs, which the engineers generated based on the most common types of cars in the world today. Each design is represented in 3D form and includes information on the car’s aerodynamics — the way air would flow around a given design, based on simulations of fluid dynamics that the group carried out for each design.
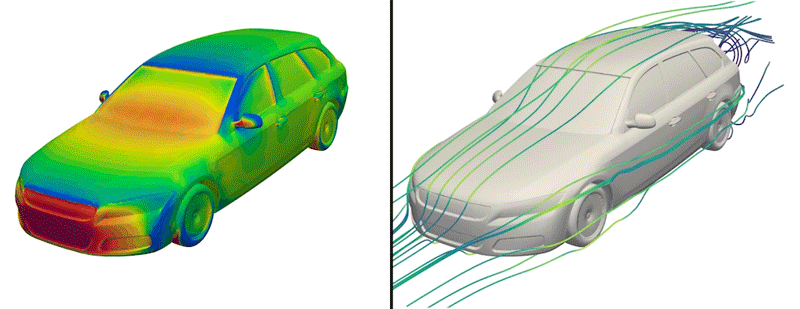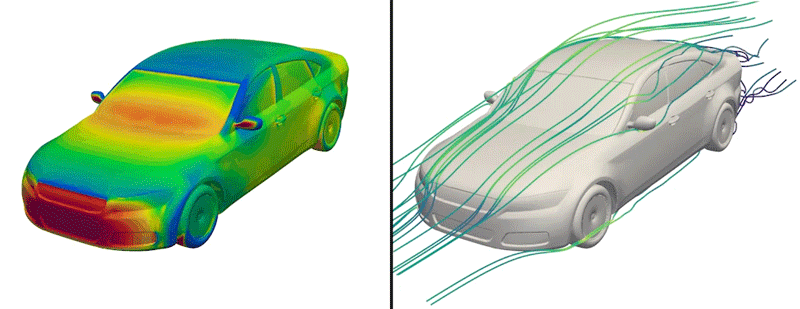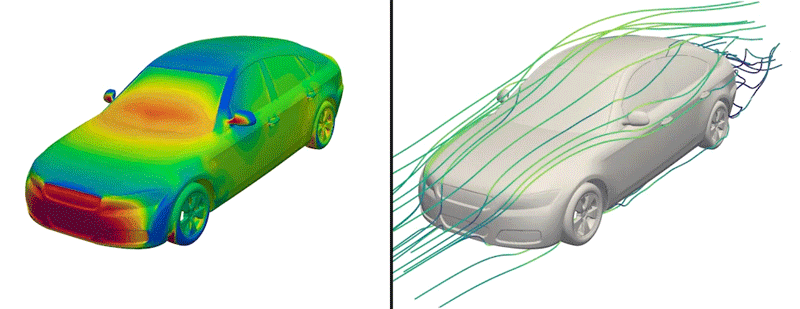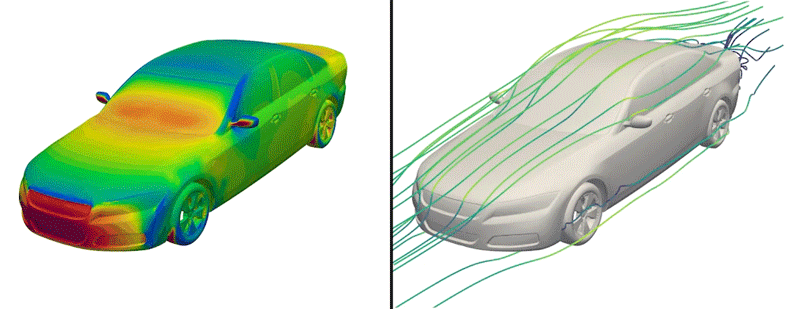
Credit: Courtesy of Mohamed Elrefaie
Each of the dataset’s 8,000 designs is available in several representations, such as mesh, point cloud, or a simple list of the design’s parameters and dimensions. As such, the dataset can be used by different AI models that are tuned to process data in a particular modality.
DrivAerNet++ is the largest open-source dataset for car aerodynamics that has been developed to date. The engineers envision it being used as an extensive library of realistic car designs, with detailed aerodynamics data that can be used to quickly train any AI model. These models can then just as quickly generate novel designs that could potentially lead to more fuel-efficient cars and electric vehicles with longer range, in a fraction of the time that it takes the automotive industry today.
“This dataset lays the foundation for the next generation of AI applications in engineering, promoting efficient design processes, cutting R&D costs, and driving advancements toward a more sustainable automotive future,” says Mohamed Elrefaie, a mechanical engineering graduate student at MIT.
Elrefaie and his colleagues will present a paper detailing the new dataset, and AI methods that could be applied to it, at the NeurIPS conference in December. His co-authors are Faez Ahmed, assistant professor of mechanical engineering at MIT, along with Angela Dai, associate professor of computer science at the Technical University of Munich, and Florin Marar of BETA CAE Systems.
Filling the data gap
Ahmed leads the Design Computation and Digital Engineering Lab (DeCoDE) at MIT, where his group explores ways in which AI and machine-learning tools can be used to enhance the design of complex engineering systems and products, including car technology.
“Often when designing a car, the forward process is so expensive that manufacturers can only tweak a car a little bit from one version to the next,” Ahmed says. “But if you have larger datasets where you know the performance of each design, now you can train machine-learning models to iterate fast so you are more likely to get a better design.”
And speed, particularly for advancing car technology, is particularly pressing now.
“This is the best time for accelerating car innovations, as automobiles are one of the largest polluters in the world, and the faster we can shave off that contribution, the more we can help the climate,” Elrefaie says.
In looking at the process of new car design, the researchers found that, while there are AI models that could crank through many car designs to generate optimal designs, the car data that is actually available is limited. Some researchers had previously assembled small datasets of simulated car designs, while car manufacturers rarely release the specs of the actual designs they explore, test, and ultimately manufacture.
The team sought to fill the data gap, particularly with respect to a car’s aerodynamics, which plays a key role in setting the range of an electric vehicle, and the fuel efficiency of an internal combustion engine. The challenge, they realized, was in assembling a dataset of thousands of car designs, each of which is physically accurate in their function and form, without the benefit of physically testing and measuring their performance.
To build a dataset of car designs with physically accurate representations of their aerodynamics, the researchers started with several baseline 3D models that were provided by Audi and BMW in 2014. These models represent three major categories of passenger cars: fastback (sedans with a sloped back end), notchback (sedans or coupes with a slight dip in their rear profile) and estateback (such as station wagons with more blunt, flat backs). The baseline models are thought to bridge the gap between simple designs and more complicated proprietary designs, and have been used by other groups as a starting point for exploring new car designs.
Library of cars
In their new study, the team applied a morphing operation to each of the baseline car models. This operation systematically made a slight change to each of 26 parameters in a given car design, such as its length, underbody features, windshield slope, and wheel tread, which it then labeled as a distinct car design, which was then added to the growing dataset. Meanwhile, the team ran an optimization algorithm to ensure that each new design was indeed distinct, and not a copy of an already-generated design. They then translated each 3D design into different modalities, such that a given design can be represented as a mesh, a point cloud, or a list of dimensions and specs.
The researchers also ran complex, computational fluid dynamics simulations to calculate how air would flow around each generated car design. In the end, this effort produced more than 8,000 distinct, physically accurate 3D car forms, encompassing the most common types of passenger cars on the road today.
To produce this comprehensive dataset, the researchers spent over 3 million CPU hours using the MIT SuperCloud, and generated 39 terabytes of data. (For comparison, it’s estimated that the entire printed collection of the Library of Congress would amount to about 10 terabytes of data.)
The engineers say that researchers can now use the dataset to train a particular AI model. For instance, an AI model could be trained on a part of the dataset to learn car configurations that have certain desirable aerodynamics. Within seconds, the model could then generate a new car design with optimized aerodynamics, based on what it has learned from the dataset’s thousands of physically accurate designs.
The researchers say the dataset could also be used for the inverse goal. For instance, after training an AI model on the dataset, designers could feed the model a specific car design and have it quickly estimate the design’s aerodynamics, which can then be used to compute the car’s potential fuel efficiency or electric range — all without carrying out expensive building and testing of a physical car.
“What this dataset allows you to do is train generative AI models to do things in seconds rather than hours,” Ahmed says. “These models can help lower fuel consumption for internal combustion vehicles and increase the range of electric cars — ultimately paving the way for more sustainable, environmentally friendly vehicles.”
This work was supported, in part, by the German Academic Exchange Service and the Department of Mechanical Engineering at MIT.