The future of last-mile deliveries holds promise for customers, driven by emerging trends poised to reshape what is possible in the logistics industry by 2030. From the electrification of delivery fleets to the proliferation of multimodal delivery solutions, companies are exploring novel approaches to enhance customer…
What is Chain-of-Thought (CoT) Prompting? Examples & Benefits
In recent years, large language models (LLMs) have made remarkable strides in their ability to understand and generate human-like text. These models, such as OpenAI’s GPT and Anthropic’s Claude, have demonstrated impressive performance on a wide range of natural language processing tasks. However, when it comes…
Generative AI to digital twins: Powering the AI revolution
Generative AI is revolutionizing technology, from human-like chatbots to digital twins. This article delves into the high-performance computing (HPC) challenges and solutions essential for deploying these groundbreaking innovations….
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Recent frameworks attempting at text to video or T2V generation leverage diffusion models to add stability in their training process, and the Video Diffusion Model, one of the pioneers in the text to video generation frameworks, expands a 2D image diffusion architecture in an attempt to…
A Practical Guide to Making the Most of Your Investment in AI
POV: You’ve heard a lot of noise about AI, and so you decide to do your own research. No matter where you turn, an expert expounds on AI’s benefits and business-unlocking potential, and so you conclude that, yes, there is a business case to be made…
How the Internet of Things (IoT) became a dark web target – and what to do about it – CyberTalk
By Antoinette Hodes, Office of the CTO, Check Point Software Technologies.
The dark web has evolved into a clandestine marketplace where illicit activities flourish under the cloak of anonymity. Due to its restricted accessibility, the dark web exhibits a decentralized structure with minimal enforcement of security controls, making it a common marketplace for malicious activities.
The Internet of Things (IoT), with the interconnected nature of its devices, and its vulnerabilities, has become an attractive target for dark web-based cyber criminals. One weak link – i.e., a compromised IoT device – can jeopardize the entire network’s security. The financial repercussions of a breached device can be extensive, not just in terms of ransom demands, but also in terms of regulatory fines, loss of reputation and the cost of remediation.
With their interconnected nature and inherent vulnerabilities, IoT devices are attractive entry points for cyber criminals. They are highly desirable targets, since they often represent a single point of vulnerability that can impact numerous victims simultaneously.
Check Point Research found a sharp increase in cyber attacks targeting IoT devices, observing a trend across all regions and sectors. Europe experiences the highest number of incidents per week: on average, nearly 70 IoT attacks per organization.
 became a dark web target – and what to do about it – CyberTalk")
Gateways to the dark web
Based on research from PSAcertified, the average cost of a successful attack on an IoT device exceeds $330,000. Another analyst report reveals that 34% of enterprises that fell victim to a breach via IoT devices faced higher cumulative breach costs than those who fell victim to a cyber attack on non-IoT devices; the cost of which ranged between $5 million and $10 million.
Other examples of IoT-based attacks include botnet infections, turning devices into zombies so that they can participate in distributed denial-of-service (DDoS), ransomware and propagation attacks, as well as crypto-mining and exploitation of IoT devices as proxies for the dark web.
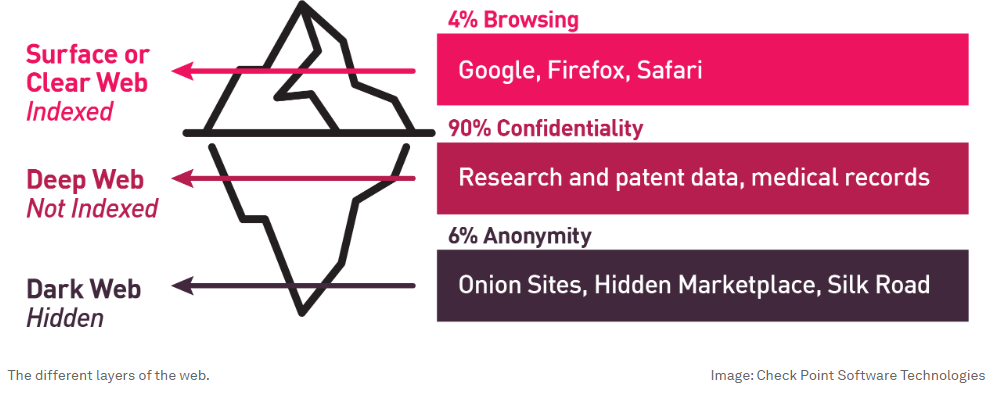
The dark web relies on an arsenal of tools and associated services to facilitate illicit activities. Extensive research has revealed a thriving underground economy operating within the dark web. This economy is largely centered around services associated with IoT. In particular, there seems to be a huge demand for DDoS attacks that are orchestrated through IoT botnets: During the first half of 2023, Kaspersky identified over 700 advertisements for DDoS attack services across various dark web forums.
IoT devices themselves have become valuable assets in this underworld marketplace. On the dark web, the value of a compromised device is often greater than the retail price of the device itself. Upon examining one of the numerous Telegram channels used for trading dark web products and services, one can come across scam pages, tutorials covering various malicious activities, harmful configuration files with “how-to’s”, SSH crackers, and more. Essentially, a complete assortment of tools, from hacking resources to anonymization services, for the purpose of capitalizing on compromised devices can be found on the dark web. Furthermore, vast quantities of sensitive data are bought and sold there everyday.
AI’s dark capabilities
Adversarial machine learning can be used to attack, deceive and bypass machine learning systems. The combination of IoT and AI has driven dark web-originated attacks to unprecedented levels. This is what we are seeing:
- Automated exploitation: AI algorithms automate the process of scanning for vulnerabilities and security flaws with subsequent exploitation methods. This opens doors to large-scale attacks with zero human interaction.
- Adaptive attacks: With AI, attackers can now adjust their strategies in real-time by analyzing the responses and defenses encountered during an attack. This ability to adapt poses a significant challenge for traditional security measures in effectively detecting and mitigating IoT threats.
- Behavioral analysis: AI-driven analytics enables the examination of IoT devices and user behavior, allowing for the identification of patterns, anomalies, and vulnerabilities. Malicious actors can utilize this capability to profile IoT devices, exploit their weaknesses, and evade detection from security systems.
- Adversarial attacks: Adversarial attacks can be used to trick AI models and IoT devices into making incorrect or unintended decisions, potentially leading to security breaches. These attacks aim to exploit weaknesses in the system’s algorithms or vulnerabilities.
Zero-tolerance security
The convergence of IoT and AI brings numerous advantages, but it also presents fresh challenges. To enhance IoT security and device resilience while safeguarding sensitive data, across the entire IoT supply chain, organizations must implement comprehensive security measures based on zero-tolerance principles.
Factors such as data security, device security, secure communication, confidentiality, privacy, and other non-functional requirements like maintainability, reliability, usability and scalability highlight the critical need for security controls within IoT devices. Security controls should include elements like secure communication, access controls, encryption, software patches, device hardening, etc. As part of the security process, the focus should be on industry standards, such as “secure by design” and “secure by default”, along with the average number of IoT attacks per organization, as broken down by region every week.
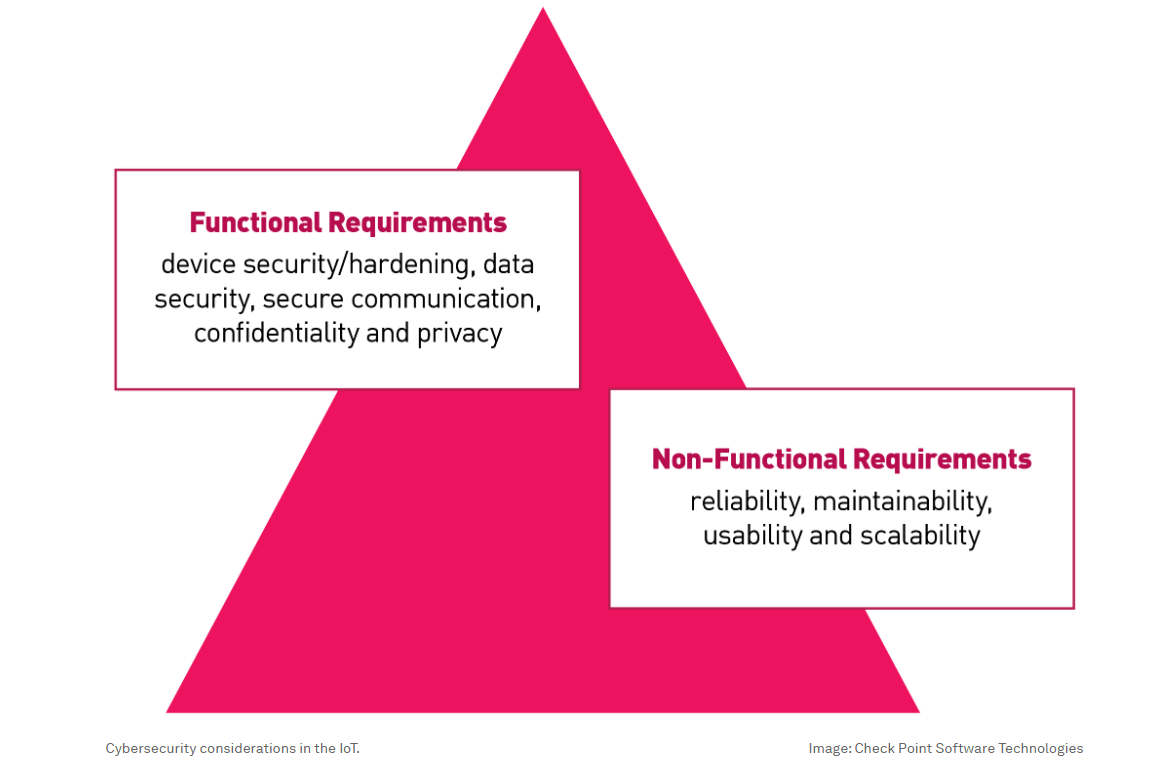
Collaborations and alliances within the industry are critical in developing standardized IoT security practices and establishing industry-wide security standards. By integrating dedicated IoT security, organizations can enhance their overall value proposition and ensure compliance with regulatory obligations.
In today’s cyber threat landscape, numerous geographic regions demand adherence to stringent security standards; both during product sales and while responding to Request for Information and Request for Proposal solicitations. IoT manufacturers with robust, ideally on-device security capabilities can showcase a distinct advantage, setting them apart from their competitors. Furthermore, incorporating dedicated IoT security controls enables seamless, scalable and efficient operations, reducing the need for emergency software updates.
IoT security plays a crucial role in enhancing the Overall Equipment Effectiveness (a measurement of manufacturing productivity, defined as availability x performance x quality), as well as facilitating early bug detection in IoT firmware before official release. Additionally, it demonstrates a solid commitment to prevention and security measures.
By prioritizing dedicated IoT security, we actively contribute to the establishment of secure and reliable IoT ecosystems, which serve to raise awareness, educate stakeholders, foster trust and cultivate long-term customer loyalty. Ultimately, they enhance credibility and reputation in the market. Ensuring IoT device security is essential in preventing IoT devices from falling into the hands of the dark web army.
This article was originally published via the World Economic Forum and has been reprinted with permission.
For more Cyber Talk insights from Antoinette Hodes, please click here. Lastly, to receive stellar cyber insights, groundbreaking research and emerging threat analyses each week, subscribe to the CyberTalk.org newsletter.
What Went Wrong With the Humane AI Pin?
Humane, a startup founded by former Apple employees Imran Chaudhri and Bethany Bongiorno, recently launched its highly anticipated wearable AI assistant, the Humane AI Pin. Now, the company is already looking for a buyer. The device promised to revolutionize the way people interact with technology, offering…
Ugur Tigli, Chief Technical Officer at MinIO – Interview Series
Ugur Tigli is the Chief Technical Officer at MinIO, the leader in high-performance object storage for AI. As CTO, Ugur helps clients architect and deploy API-driven, cloud-native and scalable enterprise-grade data infrastructure using MinIO. Can you describe your journey to becoming the CTO of MinIO, and how your…